
Executive summary
Data shapes our daily lives and permeates the economic and social landscape of every country in the world.[i] Access to new data sources and shifts in technology have generated critical insights into the progress and pitfalls of tracking the United Nations’ (UN) Sustainable Development Goals (SDGs). Meanwhile, widespread data collection and use have transformed how people advocate for change and how decision makers understand and address community needs.
Yet barriers and entrenched inequalities continue to hinder data’s potential to improve lives. Far too many people remain excluded from or invisible in data while others are harmed by their inclusion in it.[ii] Existing data is left unused or underused by policymakers.[iii] Top-down data governance solutions do not allow space for people to hold those in power accountable.[iv] Development agencies collect and use data primarily at the behest of donors, who are often out-of-touch with local governments and civil society.[v] Data and automated decision making reinforce structural inequalities—largely behind the scenes.[vi] These inequities further concentrate the power and benefits of data in the hands of a small group of decision makers.
Addressing these harms and pitfalls is critical to harnessing the full potential of data to improve lives. Yet, despite efforts by individuals and agencies and in local contexts, unprecedented levels of public dialogue, debate, and attention to these issues has not translated into widespread, collective action within the development sector to tackle the unequal power dynamics that all too often underpin the design, collection, use, and governance of data.
The Data Values Project set out in early 2021 to address this gap and to understand what principles should underpin the future of data for development. Through consultations with more than 330 people from 63 countries, a consensus emerged on the need to critically examine the ways that power is distributed in the production, sharing, and use of data, and in how data use and governance can challenge or exacerbate existing power imbalances.
This paper sets out the key themes that emerged from the consultation and describes a collective vision for a fair data future with agency, accountability, and action as its core features. Agency in data refers to having power to shape personal and/or community data and deciding whether, when, and with whom to share it. Accountability in data means that people have access to mechanisms to shape data governance decisions and to hold the powerful accountable. Data in action refers to the imperative of data producers and decision makers to use and share data to improve lives.
Building on these themes, the Data Values Project will advocate for actions that shift power to the people most affected by data production and use. This paper captures examples and stories that show these actions are already being taken by pro-active governments, companies, and civil society organizations around the world. These examples show what’s possible and already happening, while pointing to the distance that remains to achieve a fair data future for all.
This paper is only the first step to changing power imbalances in data design, collection, use, and governance. A global campaign to advocate for the values laid out in this white paper will launch in September at the United Nations General Assembly. Alongside this global campaign, champions and changemakers will lead localized advocacy efforts by tailoring messages and recommendations for actions at the local, sectoral, and regional levels.
The Data Values Project envisions a world where people can be equal players in the production and use of data that impacts them. This vision is for a fair data future in which the power of data is harnessed and its benefits are shared equitably to improve lives and ensure no one is left behind.
1. Introduction
Global connectivity and data innovation are driving massive social change—for better and for worse. Data shapes our daily lives and permeates the economic and social landscape of every country in the world.[vii] Widespread data collection and use present opportunities for people to lead and advocate for change and for policy makers and development leaders to better understand, address, and monitor the needs of different groups. The significance of timely data is keenly felt as the world responds to a global pandemic, tracks intensifying weather, and grapples with political and economic polarization, supercharged by online interactions.
Our ability to rapidly gather information has profound implications for those tasked with supporting people’s wellbeing. Seismic technological changes have outpaced most countries’ ability to research, understand, respond to, and regulate such shifts. Meanwhile, private companies have capitalized on these changes, driving innovation in data use that amasses considerable wealth and expands opportunities for many people, even while leaving others behind. By contrast, public sector and non-profit spending on data falls far short of its potential.[viii] Meanwhile, a series of high-profile data breaches and abuses have shown the widespread need for more robust data governance.[ix],[x]
Amidst increasing fears of exclusion and harm perpetrated by data-driven systems, in early 2021, the Data Values Project set out to learn what principles should underpin the future of data for development to unlock the enormous potential of data for good. What emerged was the need to critically examine the ways that power is distributed in the production, sharing, and use of data and in how data use and governance can challenge or exacerbate existing power imbalances.
This white paper lays out a vision and recommendations focused on increasing personal and collective agency in data, accountability in data governance, and evidence-based action for public good… Though our focus is on data, this is a profoundly non-technical, values-driven agenda about power and equity."
The analysis and recommendations in this paper are aimed at data producers and users, including governments, donors, digital rights advocates, development practitioners, non-governmental organizations, and businesses, who can contribute to realizing this vision. The aim is to provide a framework for global advocacy that serves as an impetus for immediate actions at the local, community, and sectoral levels and fosters continued experimentation to develop new solutions. Though our focus is on data, this is a profoundly non-technical, values-driven agenda about power and equity.
1.1 Rising inequality and declining trust in the digital age
Access to new data sources and shifts in technology have dramatically increased our ability to measure and track progress toward the United Nations (UN) Sustainable Development Goals (SDGs). Yet scandal after scandal—from Cambridge Analytica’s use of personal data to influence elections across the globe to the sharing of Rohingya refugees’ biometric data with the Myanmar government–has underscored the ways that abuse and misuse of data and tech can reinforce unequal power structures and entrench inequality.[xi],[xii] Digital rights groups have led the charge in calling for change as people have become increasingly aware of the risks of harm stemming from the design of data systems and from data collection and use.
Rising concern about data harms has gone hand-in-hand with declining trust—both in information and evidence and in public institutions and experts around the world. In fact, the UN Secretary-General named this issue one of his five priority commitments for 2022.[xiii] Global trust in policy makers and in the collection and use of personal data are at an all-time low.[xiv] Civic space is shrinking. Nine out of 10 people in 2021 lived in countries where civic freedoms had been severely restricted.[xv] Some policy makers have intentionally stifled dissent or suppressed freedoms through internet shutdowns, personal and biometric data collection, and the spread of misinformation.[xvi] As the guardrails for ensuring that data is trustworthy are weakened, trust in institutions declines. Meanwhile, civil society organizations and communities have continued to advocate for the right to freely express their views and draw attention to their concerns.
COVID-19 has resulted in a shift in public consciousness around data—both as a tool to empower and to oppress.[xvii]Most countries have seen broad public engagement (and dissent) around the issues of vaccine access, health data sharing, and contact tracing apps. Meanwhile, the role of timely, high-quality data in responding to public crises has never been more clear, and many governments are working with partners to make the most of it. COVID-19 has underlined the recent convergence of data-focused policy and public discussion.[xviii],[xix]
1.2 Reimagining data, power, and development
In 2015, the data for development community was characterized by broad optimism that innovation and data-driven development would unleash prosperity and opportunity.[xx] Better data would lead to better and more targeted services while disaggregation and filling data gaps would propel the Leave No One Behind (LNOB) agenda forward.[xxi] Since then, there’s been some promising progress. A push to develop more inclusive data to track national progress toward the SDGs has generated unprecedented quantities of new and disaggregated data for development from a wide range of sources. National statistical agencies working on inclusion in Colombia, Kenya, Canada, and other places have accelerated conversations around shifting power structures in data. Recognition of these issues at the global level is reflected in the UN Statistical Commission’s work on data stewardship and the Secretary General’s data strategy in addition to other work by international organizations.[xxii],[xxiii] Civil society organizations are becoming much more sophisticated in how they collect, analyze, and advocate for more inclusive data.[xxiv] But there’s still a long way to go toward realizing just data systems. Uneven progress rests against a broader reckoning of the development sector, which—rocked by high-profile scandals—faces chronic underfunding and reflects power inequities inherent to global systems.
Digitization is rapidly transforming economies and is a central focus of development cooperation efforts.[xxv] Data is the currency of digital transformation, driving changes to systems for decision making and service delivery. Current discourse on inclusion in digital transformation focuses heavily on expanding access to digital tools and protecting people’s privacy.
Without addressing the ways that data can exacerbate or alleviate inequalities, the push for digital transformation risks reproducing unjust analog systems."
Far too many people remain excluded from data, rendered invisible by official statistics and other data sources.[xxvi]Others are harmed by their inclusion in data, which can pose dangers to their privacy, safety, and autonomy.[xxvii]Existing data is left unused or underused by policy makers.[xxviii] Many data governance solutions are top-down and do not allow space for people to influence outcomes that will affect them or to hold those in power accountable.[xxix]Development agencies collect and use data primarily at the behest of donors, who often duplicate efforts and are out-of-touch with the priorities of local governments and civil society.[xxx] Data and automated decision making can reinforce structural inequalities, largely behind the scenes.[xxxi] These inequities further concentrate the power and benefits of data in the hands of a small group of decision makers in wealthy countries.
There is now more public dialogue, debate, and attention being paid to these issues than ever before. This awareness has yet to translate into collective action within the development sector to tackle the unequal power dynamics that often underpin the design, collection, use, and governance of data. Despite many valuable efforts by individuals, agencies, and governments to address these concerns, there is no coherent and widespread action across development and humanitarian sectors to drive fairer data systems.
As the deadline for delivering on the SDGs looms, there is an urgent need to reimagine the relationship between data, power, and development and to build consensus around a practical vision for a fairer data future. That’s where the Data Values Project comes in."
1.3 Our role and approach
1.3.1 Why the Data Values Project?
The Data Values Project is a response to calls from across the Global Partnership for Sustainable Development Data’s (the Global Partnership) network of partners to articulate a clearer stance on normative considerations that should guide data in development and develop an agenda for change through collective advocacy.[xxxii]
The Data Values Project is led by members of the Global Partnership’s Technical Advisory Group and Secretariat team. In 2021, we set out to listen to the views of individuals across countries and organizations. We sought to identify areas of consensus on what needs to change and to explore potential solutions and new approaches. Since June 2021, more than 355 people from more than 200 organizations and 63 countries have contributed to the Data Values Project through writing, conversations, focus groups, and the public consultation of this paper in draft form.
At the heart of these contributions is a focus on centering the perspectives of people and communities who have been too often overlooked or harmed by established data practices and systems. During the consultation, we engaged with a cross-section of the data for development community through the Global Partnership’s network which includes national statistical offices, private companies, aid agencies, international organizations, local non-profits, and technical experts. We also sought inputs from those who do not identify as part of this community, such as grassroots organizations that seek to build evidence bases with communities, private companies, and data producers who do not explicitly frame their work around the development agenda.
1.3.2 Why this white paper?
Drafted by members of the Global Partnership’s Secretariat team, this white paper distills the results of the consultation. The white paper builds on the ingenuity, experiences, and expertise of many individuals and organizations and on prior work by the World Bank, the UN (including the Secretary-General’s Roadmap for Digital Cooperation), and numerous groups involved in data research, advocacy, and practice.[xxxiii] The accompanying annex lists many of these projects and includes a sample of best practices, tools, and guidance that practically apply the themes in this paper to local and global contexts.
This white paper aims to provide conceptual clarity to the key themes emerging from the Data Values Project, shed light on best practices in the data for development space, and share recommendations for change. The focus is global, but the examples used throughout reflect the geographical makeup of the Global Partnership’s network and work.
This is a non-technical, values-driven agenda about people, power, and equity. As data and technology transform society, nothing short of our humanity is at stake."
1.3.3 What’s next?
Going forward, the thinking and recommendations in this white paper will serve as the foundation for building an action-oriented movement focused on rebalancing power in and through data. A manifesto for action will act as a springboard for collective advocacy, dialogue, and learning. Alongside this global campaign, champions and changemakers will lead localized advocacy efforts by tailoring messages and recommendations for action at the local, sectoral, and regional levels.
1.4 Structure
The structure of this paper is as follows. The Introduction situates the Data Values Project within the broader landscape of the data revolution. The Key terms and concepts section presents the conceptual framing for this paper.
The first chapter, Agency in Data, examines how power dynamics shape data systems, emphasizing that individuals and communities must be able to exercise agency in the design, production, governance, and use of data. As more equal power relationships improve participation and inclusion in data production, the chapter highlights three approaches—representation, co-creation, and review—to realize peoples' agency in data. The next chapter, Accountability in Data Governance, considers the ways that power is exercised in data governance and the importance of participatory mechanisms to hold decision makers accountable and enable people to take an active part in informing how decisions are made around data. The final chapter, Data in Action, considers the factors that enable people and organizations with power over data production and use to take action to improve people’s lives and build trust in decision makers’ transparent and responsible use of data.
The Conclusion builds on these themes by offering practical steps to realize the vision for the world we want to see. It offers targeted recommendations to development practitioners and donors, governments and policy makers, private companies, civil society organizations, and advocates who must play an active role in realizing this vision. A glossary of terms is included at the end of this document, accompanied by an annex of tools, resources, and examples of the themes in this paper in practice.
1.5 Key terms and concepts
Language is deeply political. Many of the terms in this paper lack a commonly agreed upon definition, and the paper’s ideas are rooted in decades of thinking from different disciplines and sectors. This section unpacks the Data Values Project’s approach to foundational concepts. The Glossary provides additional definitions for relevant terms, in particular, an elaboration on how “data” is used in this paper.
First, we recognize that data is a reflection of what we choose to measure—not an objective or complete picture of the world around us. Data reflects the beliefs, values, and choices of the people who set policy and those who design and collect data and related tools.[xxxiv] Likewise, data is only one piece of larger systems that exist within diverse governance and societal contexts. As the 2021 World Development Report explains, “data alone cannot solve development problems: people…are the central actors transforming data into useful information that can improve livelihoods and lives.” [xxxv] With this in mind, this paper seeks to outline the distinct ways in which people can use data and data systems to address injustice.
Underpinning this paper is a fundamental belief that data can be a tool to address power imbalances. Power is often narrowly understood as influence over how decisions are made and by whom, including in setting agendas in both the public and private sectors. Here we borrow from researchers Catherine D’Ignazio and Lauren Klein, authors of Data Feminism, who describe power as “the current configuration of structural privilege and structural oppression, in which some groups experience unearned advantages—because various systems have been designed by people like them and work for people like them—and other groups experience systematic disadvantages—because those same systems were not designed by them or with people like them in mind.”[xxxvi] Rather than viewing expressions of power as inherently malicious or oppressive, this paper sets out to show how expanding people’s participation in designing and governing data can expand the number and groups of people who benefit from data-based decision making.
Key to interrogating these power structures is participation, which refers to people’s involvement in influencing and even controlling the decisions, processes, and practices related to data that affect their lives.[xxxvii] Participation can be a means of redistributing power that allows underrepresented and excluded people and communities to actively engage in decision making and implementation. At their core, participatory processes recognize that people with lived experience have the greatest understanding of the challenges and opportunities they face and must be actively involved in order to develop effective solutions.
Power imbalances in development and policy making affect meaningful participation in decisions about how data is collected, managed, and used. Participatory development practice and literature have highlighted the subtle and not-so-subtle ways in which participation can be rigged. Having a seat at the table is not a guarantee of having one’s voice heard. If people who are not used to being listened to are invited into a space where others set the rules and define the agenda for engagement, they are likely to remain silent and the process will not benefit from their lived experiences.[xxxviii],[xxxix]
The vision outlined in this paper relies on people having the skills to understand and critically engage in decision making around data. Wide-spread data literacy, on the one hand, and communicative processes that enable people without such skills to engage with critical information on the other, are cornerstones of equitable and participatory data systems. People at all levels of leadership in public and private institutions need confidence to understand, engage, and communicate with data. When most people think about data literacy, they think about the ability to navigate a spreadsheet of data. But data literacy is much broader; it’s the ability to critically interrogate data presented as facts and to use data for advocacy, decision making, and more. Just as literacy is analogous to language, data literacy is a two-way communicative process. Data literacy also means understanding what data we share with others and on what terms.
The three themes of the paper’s chapters—agency, accountability, and action—refer to the outcomes that characterize a just data system, from the stages of design and collection through use and re-use in decision making. Data agency in this paper means having the power to control personal and/or community data and deciding whether, when, and with whom to share it. Accountability is about the obligation for decision makers to account for their actions and for people to shape data governance decisions and hold the powerful accountable. Action refers to effective data use for public good and the role of people and partnerships, critical but under-addressed factors in ensuring that data is used to improve lives.
2. Agency in data
- Data can reinforce or challenge unequal power relationships in society, manifested in the way data renders people and groups invisible or visible.
- The way in which data is designed and produced has implications for how people, especially those who are marginalized, are represented and included in data processes and in related decision making.
- When people have agency in the design, production, and use of data, they can actively engage and influence what and how data is collected and analyzed.
- Inclusive approaches can maximize benefits, expand agency, and redistribute power, but they must be undertaken systematically so that inclusion becomes embedded across data systems.
Agency means that people have the power to play active roles in data systems and to influence decisions about their data and about the ways that data use affects them. Top-down approaches to data design and collection limit people’s exercise of agency and exacerbate existing power asymmetries in society. Inclusive approaches can expand it.
Who controls the design of data and statistical concepts and definitions has implications for how people are represented and included in data processes and resulting decisions. Inclusive approaches are important even beyond data production. Fundamental issues such as the structuring of questions, the decisions about who will ask those questions, and how the data is collected, analyzed, interpreted, and presented affect what data gaps are prioritized and ultimately how data systems are designed. Data in this way becomes an instrument that either reinforces or rebalances unequal power relationships in society. When people—especially those who have been historically excluded from decision making—actively participate in decisions about data collection, design, analysis, and use, they gain greater access to the benefits of data.
The statistics community plays an important role in the production of data and promoting inclusive approaches to data. By designing data and statistical concepts, definitions, methodologies, and quality assurance frameworks, this community influences how people are represented and included in data processes and the resulting decisions.[xl] The statistics community has made great strides in developing inclusive approaches to data in areas such as governance, gender, poverty, aging, and in using non-traditional data sources such as big data. But statisticians in the public sector are also often constrained by political priorities and by limited budgets and capacity. As the custodians of global statistical principles, statisticians have an important role to play in maintaining standards of autonomy and confidentiality to foster inclusion.
Building on this work, this chapter breaks down how data production and use affect power relationships in society. It highlights several promising approaches for increasing individual and community data agency, and it showcases how this agency contributes to a future centered around more equitable decision making and outcomes.
2.1 Unpacking data agency
Gwen Phillips is an Indigenous data advocate and member of the Ktunaxa Nation, one of Canada’s First Nations, who argues that the Canadian government’s data collection has historically focused on negative characteristics of societies like hers instead of on community assets, strengths, and abilities. Gwen says this historical focus is not by accident. “As long as others are controlling the agenda, data, and investments, we’re always going to be subject to being beggars in our homeland,” she explained.[xli] In Gwen’s view, data can be a means of oppression and of liberation.[xlii]
The government of Canada through Statistics Canada has been working with First Nations’ communities, and other marginalized communities, to address this. Statistics Canada is putting people at the center by analyzing the interactions between different sector outcomes to understand the factors that exacerbate exclusion and capture the lived experiences of these communities. As a data steward, Statistics Canada is also ensuring that data is based on consistent standards and classifications that allow international comparison to guide decision making.[xliii]
Like other historically marginalized groups, Indigenous communities around the world have experienced the adverse consequences of being excluded from data, of having no say in how they will be measured, and of having their lived experience ignored. As a result of long-standing systems of historical oppression and marginalization, many groups have been excluded from taking part in decision making processes, resulting in missed opportunities to share in the benefits and value of data.
When people and communities have agency in the production, governance, and use of data, they can influence the choices that are made about that data.
Agency is 'the capacity of people to actively and independently choose and affect change.'
For this paper, we apply this definition to data, having control over one's data and being able to choose whether, when, and with whom to share it as well as whether and how one is counted.[xliv]
Agency differs at personal and community levels. At the individual level, agency includes control over one's personal data (such as identification number, medical records, and location data) and the ability to choose when, with whom, and for what purposes to share it. But simply understanding agency at the individual level is not enough. The design, collection, and use of personal data can have broad impacts on groups and community members.[xlv], [xlvi] Collective agency refers to the need for groups and communities to take part in data design, collection, analysis, interpretation, and presentation. A lack of agency at both levels means that people are excluded and unable to participate in decisions that affect their lives. It also means that their views and experiences may not be accurately reflected in data.
2.2 How data reinforces unequal power relationships in society
At the onset of the SDGs, the LNOB agenda was the central, transformative promise to reach the furthest behind and combat discrimination and inequalities within and among countries and address their root causes.[xlvii] The LNOB agenda has emphasized and advanced important efforts toward identifying inequalities and discrimination through the generation of evidence, data collection and data disaggregation. As Box 1 explains, disaggregating data by sex, disability status, and other factors is a first step towards agency in data-because inequalities are often obscured in aggregate-level data. But disaggregation is not sufficient on its own.
|
Box 1. The importance of looking beyond data disaggregation Data disaggregation is the process of ensuring that data used to generate statistics and indicators for population groups can be further broken down into one or more dimensions or characteristics (commonly sex, geographic area, age, race, ethnicity, and disability). Data disaggregation allows data users to compare population groups and to understand the situations of specific groups. Policy makers have used disaggregated data to identify at-risk populations and establish policies, programs, and legislation to protect them. For example, data from the Demographic and Health Survey revealed that, in the majority of sub-Saharan African countries, women in their teens and early twenties were disproportionately at risk of contracting HIV/AIDS. Governments responded by creating specific curricula on HIV transmission for young women and by prioritizing this population in the fight against infection.[xlviii] Sometimes disaggregated data is not enough. Disaggregation cannot improve the visibility of those who are excluded from original data collection. It is also not possible to disaggregate data sets by every relevant dimension, meaning that some inequalities will remain invisible. Therefore, decision makers and statisticians who decide which disaggregation dimensions are prioritized, have power over which disparities will be analyzed, yet their perspectives may be biased or incomplete.[xlix] As such, disaggregation is not enough to ensure that people’s agency in data leads to greater access to resources, decision making, or existing levers of power. An intersectional approach to data identifies inequalities within and between groups of people based on how an individual’s multiple identities (such as race, gender, disability status) intersect. This ensures that these factors are not intentionally or unintentionally obfuscated, consequently underestimating the roles and contributions of each person in society. Important concepts relevant to disaggregation may lack internationally agreed upon definitions or require activities beyond just data collection. The Institute of Global Homelessness, through its ‘A Place to Call Home Initiative,’ took an intersectional approach to data.[l]Their approach ranged from developing a Global Framework for Understanding Homelessness that can be easily adapted to different contexts but which allows comparable definitions between countries, ensuring that people with lived experiences informed the design of data collection and took part in data collection, analysis, and use. |
A key way that data reinforces unequal power relationships is by rendering people or groups invisible in data, undermining their agency and exacerbating inequalities. When people are not counted or are not appropriately represented in data, they are invisible to decision makers in government and development organizations.[li] Approaches that prevent people and communities from shaping data design, collection and analysis efforts based upon their own lived experiences also exacerbate their invisibility.
People may be excluded from data for a range of reasons. For example, people who live in hard-to-reach locations, who are illiterate, who lack access to digital technology, or who have a particular life situation or belong to a specific group of the population are often excluded from data sampling and data collection. Second, asking one household member to answer questions on behalf of the others (particularly on sensitive issues related to health, financial decision making, time use, and exposure to risk or violence) does not accurately capture differing constraints and opportunities within households. Household-level surveys have significant implications for people whose contributions are more likely to be underreported. Likewise, failure to register the births of children may prevent enrollment in school; and failure to gather data on children with disabilities, for example, hinders provision of accessible schooling, thus denying children with disabilities their right to quality education.
Some people may choose not to be counted because of a lack of trust in institutions or decision makers or due to perceiving no benefit to being counted. At times the choice not to be counted is for fear of the consequences, such asbusinesses being deregistered or taxed or the loss of privacy, of being recognized by governments or watchdog groups.[lii],[liii] In countries where civic and digital rights are not well-protected, being included in data can pose a serious threat to people, as it gives governments the means to surveil and control populations.[liv]
In other cases, people are misrepresented or rendered invisible in data, resulting in information that does not accurately reflect the priorities or characteristics that are important to their communities. This is true particularly in settings such as humanitarian operations involving refugees and displaced people.[lv] In these cases, data is collected for service provision, but when people are not consulted on what data should be collected and how it should be used or shared, decision makers may wield their power to manipulate priorities. This erodes people’s agency and access to resources and opportunities, particularly because the policies that are then enacted may not meet people’s needs.
Structural inequalities are reinforced when data design, collection, disaggregation, and analysis are top-down processes that measure levels of deprivation or assimilation, i.e., “How much poorer are these people in comparison with the majority?” instead of providing a more holistic picture of people's situation, reflecting their resilience and strengths, as well as needs. Inclusive and participatory approaches ensure that people and communities are actively involved and can shape these data processes.
The international statistical community has developed statistical methodologies to guide countries in producing statistics that actively involve people and their communities. The Fundamental Principles of Official Statistics, give clear guidelines to National Statistical Offices to ensure impartiality, confidentiality, and adherence to standards and methods, among other principles in producing statistics.[lvi]
Capturing robust, disaggregated, and intersectional data may require collecting larger samples or testing innovative approaches to capture the experiences of relatively small groups of people amongst larger populations and improving the availability of relevant data. Statistical agencies and other data-gathering organizations may face practical constraints to producing such data including a lack of financial resources, capacity, or adequate methodologies. As the custodians of statistical standards, National Statistical Offices (NSOs) face difficult trade-offs between producing robust statistics and avoiding exclusion. Nevertheless, examples in this chapter highlight how trailblazing data producers are experimenting with new methods, data sources, and approaches to foster inclusion and promote agency.
In a recent example from the United Kingdom (UK), advocates pointed out how nationwide inflation measures failed to factor in the experiences of low-income people for whom prices of basic food products had increased at rates several times higher than the average rate estimated by the government. “The system by which we measure the impact of inflation is fundamentally flawed—it completely ignores the reality and the REAL price rises for people on minimum wages, zero hour contracts, food bank clients, and millions more,” anti-poverty campaigner Jack Monroe argued on Twitter.[lvii] This increases the risk of enacting policies that further harm people whose experiences were not factored into inflation estimates.[lviii] In response, the UK Office of National Statistics announced ongoing plans to develop a more accurate and expansive measure of household inflation.[lix]
The increase in production and use of privately held data has led to practices that risk further erosion of individual and community agency in data.[lx] When decision making is contracted out to artificial intelligence (AI) without involving groups whose lives are affected by these algorithms, the consequences can be devastating in terms of bad decisions, unintended consequences, and missed opportunities. Misuse of historical data (resulting from built in bias and stereotypes affecting the datasets) as well as automatic classification can harm people who are already vulnerable. Take, for example, the COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) system in the United States, which has been found to be biased against Black people. The program is used by judges to predict whether defendants should be detained or released on bail pending trial by assigning a risk score based on the likelihood to commit a future offense and therefore guiding judges to give longer detention periods to defendants with higher risk scores.[lxi] Such systems exacerbate structural and systemic inequalities. Efforts from organizations like the Center for Policing Equity work with American police departments to minimize racial bias in data-driven systems.[lxii]
2.3 How data challenges power relationships in society
Data can also be a means of enhancing people and communities’ agency in decision making and resource allocation, increasing their visibility to decision makers in government and development organizations, and creating pathways for transparency and accountability. For example, foundational public data systems such as birth, marriage, divorce, identity, and death registration systems enable people to access services and exercise their civic duties. Information from these systems guides governments in allocating resources and deciding where to prioritize efforts and investments.[lxiii]Collecting data that reflects societal inequities among people based on race, gender, and other intersecting factors also enables policy makers to address disparities.
Big data and Artificial Intelligence can also be harnessed by NSOs to improve efficiency, timeliness, granularity and comprehensiveness of data collection and statistical production.[lxiv] For example, to ensure COVID-19 vaccines reached people with the greatest need in Guatemala, geospatial mapping software provider Fraym worked with the government and other actors to design an equitable vaccine allocation model to guide the national vaccination plan. The model identified population characteristics at the hyperlocal level, prioritizing people based on risk factors such as age and socioeconomic status and indicators such as utilization of health services.[lxv]
Analytical approaches beyond standard disaggregation can surface intersecting inequalities and reveal social norms and structural inequalities that may present themselves in data.[lxvi] On a global scale, the Multidimensional Poverty Index (Global MPI) uses traditional survey data to analyze intersecting experiences of poverty, such as housing, nutrition, and cooking fuel, to identify “the poorest among the poor.”[lxvii] For the first time in 2021, the Global MPI report looked at poverty data disaggregated by race and ethnicity, uncovering “stark inequalities” that had previously been obscured by aggregated data.[lxviii] Similarly, the 2022 SDG Gender Index developed by Equal Measures 2030 with support from the Tableau Foundation applies a gender lens to the 17 SDGs. This index uncovers areas in which women lag behind men—for example, in access to education and digital banking—to enable policy makers to target programs that help close the gender divide in key development outcomes.[lxix] The international statistical community has also increased efforts to provide leadership on intersectional approaches to data, particularly for gender. This is reflected in the work of the Interagency and Expert Group on Gender Statistics (IAEG-GS).[lxx]
Beyond data disaggregation and intersectional analyses, it’s critical to explore ways for people and communities, especially those who are marginalized, to participate at every stage of data creation, analysis, and use. For example, Statistics Canada recently established a disaggregated data action plan which prioritizes the voices of diverse groups and communities to better reflect their experiences and meet their data needs.[lxxi] Through direct involvement in data processes, people can surface different perspectives and influence decision making and implementation. In some instances, the voices of these diverse groups may be captured through qualitative methods such as storytelling. In India, the Poverty and Human Development Agency (PHDMA) of the government of Odisha has a network of 6,700 field officers trained to capture stories of change and lived experiences in their communities.[lxxii]
When the Centre for Internet & Society (CIS) undertook a project to build digital platforms in the domestic and care work sectors in India, researchers initially planned to ask direct questions about how caste discrimination impacted women from Dalit and Indigenous communities.[lxxiii] But members of the Domestic Workers Union who were included as project co-researchers cautioned against asking specific types of questions based on their personal experiences of domestic work and the sensitivity of the subject. As a result, CIS researchers adjusted the questions. The answers they received brought the realities of domestic workers' experiences to the forefront, enabling more robust data collection and project design. Such person-focused and inclusive approaches lead to better data and research design and consequently better policies and outcomes.[lxxiv]
Through more participatory and inclusive data and data processes, people and communities can build their data literacy skills and their capacity to use data to create and advocate for change. Such data approaches also create incentives and mechanisms for people to access data and provide feedback on the quality of services. Efforts to publish data or make data open and accessible, while safeguarding privacy, ensure that people can interrogate, influence, and even lead decision making. These are the foundations for transparency and accountability, which strengthen individuals and communities’ agency and trust in data systems and decision makers. For example, as part of the Innovation to Inclusion (i2i) program, Organizations for Persons with Disabilities in Bangladesh and Kenya implemented data driven advocacy strategies to strengthen digital and tech-based solutions for disability inclusion. Through this project, the organizations learned that having clear goals for advocacy backed by data and relationships were key ingredients for concrete progress. By applying this learning, they were able to influence physical changes in government offices to enable accessibility.[lxxv]
2.4 Rebalancing unequal power dynamics: adapting features of inclusion
This section highlights practical applications of inclusion that support people to gain agency in data. The features of inclusive approaches are broadly termed representation, co-creation, and review and explained in further detail in Figure 1. These approaches enable people to engage directly in data production and/or participate in co-creation and decision making around what data is collected and how it should be collected and analyzed, building their data skills in the process. No single approach is sufficient, and each approach involves trade-offs that may compromise people’s agency in data.
|
Figure 1. Features of inclusive data systems Representation Standard disaggregation methods aligned with SDG target 17.18 and the LNOB agenda surface group-level inequalities and differences by “income, gender, age, race, ethnicity, migratory status, disability, geographic location” and more. Representation through disaggregation is a prerequisite to data agency. Example: The Wa Community in Myanmar (located in the northern, non-government-controlled region) were included in the national census for the first time in 2014. This facilitated a development process to reach women and girls in particular from a remote location.[lxxvi] Co-creation In co-creation, data is created with rather than for or about people. The result is that people can influence the data that is produced, and they can produce data that they deem relevant for their needs. The key feature of co-creation is that, in deciding what matters to them, people take part in defining data concepts, classifications, and standards and informing decision making.[lxxvii] Sometimes these efforts are led by governments working with communities to shape how they are defined and how data is collected, and at times these efforts are led by non-state actors. Example: The Central Bureau of Statistics of Nepal and the National Human Rights Commission among others are working with youth and women to generate data on their situations.[lxxviii] Citizen-generated data methods such as Open Mapping (e.g. HOT), citizen science, sub-national data collection by citizens, and disability data collection enable citizens to decide what issues are important to them, collect the data and engage their leaders with the data.[lxxix], [lxxx] Review Working arrangements such as committees or task forces convene experts and community representatives—often from different disciplines—to lead assessments of data gaps, biases, etc. Examples: The Washington Group on Disability Statistics was established twenty years ago to develop internationally comparable disability measures. The development of these measures has been an inclusive process that has brought together government and non-government stakeholders. The international statistical community through the UN Statistics Division has also established city groups on statistical methodologies in which communities who are directly affected review data, for example, on governance and aging.[lxxxi] Some committees or task forces may be within a specific country, as done in the UK through the inclusive data task force. |
When people are represented in data, efforts are made to ensure that they are visible in data collection, design, analysis, and presentation. Increasing representation often results from collective advocacy among different stakeholders including human rights groups and advocates. When people care deeply about issues and are willing to advocate for change, data producers can respond by expanding definitions and data collection efforts. For example, the Kenya National Bureau of Statistics added a third gender option (intersex) to the national census in 2019 after working closely with human rights groups.[lxxxii] This doesn’t mean that representation is easy or straightforward, a fact that is especially evident when establishing definitions of individual and group identity such as race and ethnicity.[lxxxiii]Again, people may not wish to share their data or be visible in data out of fear of reprisal.
People are more likely to care about data when they are involved in creating it. This is co-creation, when the views, lived experiences, and perceptions of communities are incorporated into the design phase of data-focused projects. This can happen directly, as in the Open Mapping projects through Humanitarian OpenStreetMap Team (HOT), or through representative consultation, such as the example from Colombia in Box 2.[lxxxiv] In both cases, people’s views are factored in and they receive feedback from decision makers at every step of data design, collection, and use. More broadly, when people are involved in co-creation, their stake in the data will also increase. However, co-creation can be time and resource-intensive, especially in settings that require quick action. Co-creation also requires a level of knowledge of the issues and a culture of willingness among citizens to engage in sharing views and experiences. Additionally, co-created data may not meet the criteria for official statistics or be regionally (or internationally comparable), but it can supplement or complement official data by adding granularity and nuance that highlights people's lived experiences.
Finally, review provides a means by which people can provide feedback and contribute to how data is created, processed, and used based on specific regional or community priorities. An example of this occurred in mid-2020, when the GovLab held a series of consultations on reusing personal data to respond to COVID-19. Policy makers, citizens, and advocates shared their expectations and concerns.[lxxxv] Through this approach, committees or groups are tasked with ensuring that people’s needs and priorities are included and protected in data, and allowing for extensive consultation with communities. As the custodians of data quality, NSOs can systematically adopt review mechanisms to ensure that inclusion is prioritized alongside statistical rigor, making this approach both scalable and sustainable. Review processes run the risk of tokenism, however, and require people to select trusted intermediaries to steward and represent their communities.
Creating avenues for participation in the design, collection, analysis, and use of data is critical to fostering agency. The next chapter unpacks participation, building on Ada Lovelace Institute’s framework of participatory data stewardship with a focus on participation in data governance.[lxxxvi] This framework is applicable because it highlights the need to ensure that data design, production, use and analysis is inclusive and meets the needs of communities, which ultimately builds trust in the system.
|
Box 2. Counting race in the Colombian census With more than ten years since the last formal population count, Colombia’s national statistics office (Departamento Administrativo Nacional de Estadística or DANE) faced intense scrutiny ahead of the 2018 census. Previous censuses had asked questions of race but faced challenges of “poor wording and inadequate geographic representation” as well as “longstanding, culturally embedded discrimination” that resulted in “gross undercounting” among populations that historically lacked access to levers of power.[lxxxvii] Community leaders, recognizing the importance of being counted, actively sought to shape the 2018 census. In the context of decades of conflict and historic undercounting of marginalized communities, “the risks of omission are very high,” a researcher from Colombia’s National University told reporters in 2016. “A very strong relationship between DANE and these organizations is needed for the logistics of this operation.” In response, from 2015, Afro-Colombian and Indigenous community members and organizations consulted with officials from DANE to develop better measurements for race and to train enumerators to be sensitive when asking questions about race. An example of this was not assuming someone’s ethnicity because of skin color or clothing. For the first time, Indigenous communities were responsible for the census operations (transport and staff) in their territories. Collaboration led to a public education campaign to increase Colombians’ understanding and willingness to participate in the census.[lxxxviii] While the census results were initially contested by Afro-Colombians, DANE has responded by combining census data with identification and georeferenced data and with other data sources such as administrative records to identify omitted populations in the census.[lxxxix] With AI, DANE has also been able to scale up existing poverty estimates from 1,123 data points to 78,000 data points—a 70-fold increase.[xc], [xci] |
2.5 Setting our sights on data agency
Examples in this section have demonstrated that there is no one-size-fits-all approach. A combination of these features should be applied to maximize benefits and expand people’s agency through data. Leaders must take strategic and institutional approaches to prioritize ways to increase individual and collective agency and promote inclusion.
Approaches that build agency take a deliberate investment of time and skills, as they are about changing and challenging mindsets and shifting power. The work of the Washington Group on disability statistics has been ongoing for twenty years. Partnerships between NSOs and Indigenous communities in Colombia and Peru to revise how the censuses captured data on Indigenous people spanned over three years. Implementing the resulting methodologies required the statistical offices to navigate sensitive issues like racial self-identification. Statistical offices and other data-producing institutions often experience resource and capacity constraints, making the task even more difficult. However, examples in this section have shown what is possible, even in low-resource settings.
Driving systematic change to rebalance power and promote agency should be a core goal of data stewardship. Across public and private sectors, data stewardship has been described as a function or set of functions to facilitate the production, management, sharing, and use of data within and between organizations in a responsible and trustworthy manner.[xcii],[xciii],[xciv] Trust is fundamental to stewarding data in the public interest and therefore requires considering the power imbalances that exist in data systems and how they can be addressed through greater inclusion and participation.
This chapter has highlighted how data can reinforce or rebalance unequal power dynamics in society. The negative effects of this inequality is felt most by people and communities that are marginalized. Inclusive approaches highlight ways to increase people’s agency in data, and applying a combination of those features enables the collective agency and expands the shared benefits of data.[xcv], [xcvi]
3. Accountability in data governance
- Formal mechanisms of data governance (laws, policies, and institutions) provide frameworks for accountability but are not sufficient on their own.
- Participatory data governance mechanisms are essential for shifting power to people and fostering accountability in practice.
- Baking participation into data governance can ensure that the data systems of the future are answerable to the people they serve and that the benefits of data are shared.
- Accountability should be embedded in all stages of data governance and should not be treated as an afterthought when scrutinizing leaders and institutions. Fostering participation at all stages of governance allows affected communities to shape decisions, set expectations, and take an active role, through public pressure, in enforcement.
- To institute these mechanisms, organizations must grapple with and confront the trade-offs and additional costs inherent to broadening participation in data governance.
Individual and communities’ agency in whether and how data is collected, analyzed, and presented is not enough on its own to alleviate injustice. How data is controlled, managed, and used—and who decides how this happens—can be a means of wielding power or of balancing and diffusing it. If the structures and mechanisms set up to govern data are accountable to the public and trade-offs are well managed, then data is more likely to be used for public good and less likely to cause harm. Fostering accountable data governance requires mechanisms for people to directly participate or have their interests represented in decisions about how their data is controlled and used. It also requires that the actions of decision makers are transparent and able to be questioned and changed if necessary.
The COVID-19 pandemic has illuminated many examples of public and private entities using personal data without adequate public engagement. When the UK’s National Health Service embarked on a contract with Palantir, a U.S.-based software firm, people were outraged that the contract could allow the company to use the health data of millions of Britons for non-COVID-19 response purposes. Handing this power to a company known for its work on defense and national security significantly undermined public trust. The government’s failure to consult the public on this contract and similar arrangements was at the heart of a lawsuit brought by Foxglove and openDemocracy that eventually caused the UK government to back out of the deal.[xcvii]
In the scandal over Palantir in the UK, recourse came through the legal system, which acted to safeguard rights and establish checks and balances. The legal system on its own, though, wasn’t enough to prevent harm. Civil society activists and members of the public who spoke out played a critical role by holding the government accountable. This example demonstrates that formal remedies and “after-the-event” enforcement might not even be triggered in the absence of participatory monitoring of decisions. Furthermore, retroactive enforcement solutions do not necessarily lead to more accountable data practices over time. In this case, the UK’s National Health Service had already been involved in a similar scandal in 2015 when it collaborated with the Google-owned AI company DeepMind to develop a health data-tracking app.[xcviii]
Accountability is far too important to be left to the realm of retroactive scrutiny and enforcement. It must be established at the outset to shape data-related decisions as they are taken. Accountability should be embedded at all stages of governance, starting with involving people in decision making. This can include mediating between conflicting interests and establishing penalties for bad behavior, creating the space for ongoing scrutiny of decisions and actions as they are taken, and, finally, integrating the outcomes of this scrutiny into new decisions. New participatory data governance mechanisms, such as the “learning data governance” approach established by Understanding Patient Data, an initiative of the UK-based foundation Wellcome Trust, reflect this cyclical view of accountability. It allows people to participate in decisions about data, to scrutinize the execution of decisions, impose remedies if needed, and learn from previous decisions to improve decision making outcomes over time.[xcix]
Formal data governance mechanisms such as laws, policies, and institutions provide frameworks for accountability at local, national, and international levels of governance.
However, formal mechanisms are necessary but not sufficient to shift power to the people whose data they are designed to protect."
Participatory mechanisms of data governance are essential for accountability because they provide spaces for deliberation, consensus-building, and continuous public scrutiny as a complement to and sometimes a check on formal mechanisms. These informal mechanisms are no less important than formal laws, policies, and institutions to ensure that data systems are accountable to people.
3.1 Accountability requires action at all levels and stages
The concept of data governance has its roots in the private sector, where it refers to the practices and systems used by corporations to manage data. Understandings of data governance in public policy have recently expanded to describe “the laws and policies governments enact to govern the use of data in society.”[c] The World Bank, in its 2021 World Development Report, argues that data governance is “the tangible expression of a country’s social contract around data.”[ci]
The World Bank’s report focuses on four core components of national and international data governance, including: 1) infrastructure policies; 2) data laws and regulations; 3) economic policies; and 4) governmental institutions, as well as other institutional actors, that set standards and increase data access and reuse. Efforts to strengthen data governance within and among countries over the last decade have focused heavily on the laws, policies, and institutions described by the World Bank.
Between 2010 and 2020, 62 countries enacted data privacy laws, more than in any other decade, bringing the total number of countries with such legislation to 142 at the end of 2019.[cii] Many countries and regions are exploring bilateral and multilateral agreements that address cross border data flows while organizations and projects are establishing or refreshing their policies, protocols, and data sharing agreements. The pandemic has intensified the spotlight on the role and function of these laws, policies, and institutions, as well as the urgency of establishing or improving them in all corners of the world.[ciii]
The important work happening at the highest political levels must be extended and supported, particularly in low- and middle-income countries where legal frameworks and the institutions required to implement data laws and policies may be weak or non-existent.[civ] But establishing and strengthening these laws, policies, and institutions is only part of the story. While formal structures and top-down mechanisms of accountability are required for effective data governance, they are often designed and decided upon by a relatively small number of actors in each country or organization. On their own, they rarely provide the space for affected communities to shape decisions, or even to know or understand what those decisions are, let alone to hold leaders accountable for operating within the framework that they establish.
Formal mechanisms of data governance can have participatory dimensions built in. For example, the EU General Data Protection Regulation (GDPR) and GDPR-inspired laws establish parameters for informing data subjects about how their data will be used. They also foresee remedies and enforcement mechanisms to hold those making decisions about data accountable.
However, informing people and providing legal remedies that can only be activated after harms are incurred meets the bare minimum for standards of participation and rarely leads to people or communities being able to influence the outcome of data use through increased knowledge or understanding."
Participatory data governance mechanisms that enable people to influence decisions or outcomes provide an essential complement to formal mechanisms. These include a range of approaches, institutions and forums designed to foster transparency and participation or create space for people’s interests to be represented in data governance processes. Furthermore, they extend well beyond retroactive scrutiny of decisions and provide avenues for continuous involvement and oversight.
Participatory mechanisms can operate inside, outside, or alongside formal mechanisms of data governance to strengthen accountability in practice."
By creating pathways for accountability, participatory mechanisms give people and communities more power in data governance. They can bring a diversity of perspectives together to balance competing interests and shift power asymmetries. They can foster greater transparency through open communication and information exchange, which creates space for continuous scrutiny. They can create opportunities for learning among all stakeholders—experts and laypeople, data producers and users, government officials and community members. This builds trust, increases data literacy, and demystifies technology and data governance. Most importantly, participatory mechanisms can operate on an ongoing basis that allows them to be agile and evolve. In contrast, legislation, regulation, and institutions are slow to adapt to change and struggle to keep up with the pace of technological development. However, when accompanied by participatory mechanisms, they become better equipped to adapt to the modern fast-moving digital world.
|
Box 3. The problem with individual consent Much of the discourse around data governance focuses on privacy and protection and places the emphasis on individual consent for companies or institutions to collect and use personal data. While consent is an important cornerstone of data governance, it is increasingly viewed as insufficient on its own to foster accountability.[cv] First, it places the burden on individuals and requires them to be fully informed, skilled, and equipped to make decisions about their data. In practice, evidence suggests that very few people read privacy notices before accepting them, which indicates that the perfectly informed individual who has time to read and consent to multiple notices every time an entity wishes to collect or use data does not exist.[cvi] Second, consent relegates individuals to a passive “assent or dissent” role, without allowing them to articulate their needs and aspirations in terms of data collection and use.[cvii] It prompts people to decide whether they want to participate by forcing them to either accept a given set of conditions or be left out or denied services, without any possible intermediate or third option. Furthermore, individual consent mechanisms don’t address the way that personal data can impact people at the community or societal level.[cviii] They also don’t speak to the way big data is used in automated decision making where the goal is to derive population-level insights. This can lead to collective harms that are felt well beyond the individuals who provided consent.[cix]In other words, obtaining community consent for data collection, sharing, and use by ensuring that affected people and groups have outlets to have their views heard is equally if not more important than obtaining individual consent.[cx] |
3.2 Pathways to accountability
A central feature of participatory mechanisms is that they enable people to engage directly or indirectly in data governance. This section describes what this looks like in practice and how these mechanisms contribute to accountability.
The Ada Lovelace Institute has created a useful model for understanding participatory data stewardship by adapting Sherry Arnstein’s ladder of citizen participation.[cxi],[cxii] The ladder’s steps in Figure 2 represent levels of participation by how much power affected people or communities have and how much is ceded by decision makers. The ladder begins at informing people how their data will be governed. The next steps are: consulting them and providing feedback on their concerns, involving them to ensure their concerns are reflected, collaborating with them in the design of data governance models, and empowering people by supporting their decisions about their own governance models. Moving up the ladder toward greater participation fosters greater transparency and trust and ultimately leads to redistributing power to people.
|
Figure 2. Ladder of participation in data governance (adapted from the Ada Lovelace framework), with examples Inform
Example: Most privacy and data protection regimes established in recent years follow the example of the GDPR in that they lay out clear rights of data subjects.[cxiii] In Uruguay, data subjects have the right to be informed about why their data is collected, who will be able to access it, what the effects are of not providing the data and how they can exercise other rights concerning data access, deletion, and modification.[cxiv] Data subjects must also be notified of any change in the governance of the data following its collection. Consult
Example: In Ghana, where the Statistical Service (GSS) obtains mobile data to produce official statistics based on an agreement with Vodafone Ghana, Vodafone Foundation, and Flowminder, GSS established a Steering Committee to address requests for data from parties other than those in the agreement.[cxv] The Steering Committee includes representatives from civil society organizations that work to protect digital rights. This ensures that groups that bring a digital rights perspective can weigh in on ethical considerations in such decisions, and can hold government and private actors accountable through the decision making process. Involve
Example: Restore Data Rights is a grassroots movement campaigning for African governments to respect and protect fundamental human rights—particularly those exercised in cyberspace and over personal data—during and after the COVID-19 pandemic. Launched in November 2020, the movement is centered around a declaration that commits signatories and endorsers to transparency, inclusivity, and accountability around data governance in Africa during the pandemic.[cxvi] To date, 62 institutions and individuals have signed on, and organizers are additionally working with data protection offices in Kenya and Mauritius. The movement also established a civil society organization working group looking at long-term accountability on COVID-19 data use, ran a data protection awareness campaign in Kenya, and conducted research on how the provisions of the declaration are translated into law and practice in Kenya, South Africa, Nigeria, and Ghana, which will provide a way for the movement to assess government policies and actions against the declaration.[cxvii] Collaborate
Example: Data-Pop Alliance’s Councils for the Orientation of Development and Ethics (CODE) are advisory groups of independent and local stakeholders who provide ethical guidance for data collection and use.[cxviii] In a project focused on gender-based violence during COVID-19 in South America, concerns from CODE members about stigmatization of victims led organizers to abandon plans to create maps of violent hotspots. Instead, “no stigmatization” became the primary ethical principle to ensure the project did not violate other data-related concerns related to harm, confidentiality, and privacy. This resulted in a shift to focus on factors that affect reporting rates among domestic violence victims.[cxix] Empower
Example: The First Nations principles of OCAP—which stands for ownership, control, access, and possession—informed the First Nations Regional Health Survey, the only First Nations-governed national health survey in Canada.[cxx] Since its launch 20 years ago, it has undergone three survey cycles in over 250 First Nations communities in Canada using both Western and traditional understandings of health and well-being. Its results have been used by numerous public agencies in Canada across health, economic, and public safety domains to assess the effectiveness of programs and design policies in a way that is responsive to First Nations’ needs and aspirations.[cxxi] |
Fostering participation in data governance in one or several of the ways described by the ladder is already happening around the world and leading to greater accountability as a result, as Figure 2 explains. Councils and committees made up of local stakeholders can scrutinize a project or an organization’s data management processes to ensure it is responsive to local needs at the design and implementation stages, similar to what CODE does. Another approach is for communities to establish and implement their own data governance principles. Indigenous communities, as Figure 2 shows, have been at the forefront of establishing practical and ethical principles to govern data about their communities, starting with the recognition that accurate and timely information is key to addressing the long-lasting impacts of colonization and systemic racism. Many other innovative participatory approaches to data governance are currently being tested and researched around the world.[cxxii]
Fostering participation in data governance is not only the responsibility of public sector and civil society organizations. Private companies, too, can and should be engaged. Dozens of corporations, including data platforms and intermediaries such as 1001 Lakes, DataCave, and Meeco, have signed onto the MyData Declaration and joined the MyData Global movement since its founding in 2018. As a global network of entrepreneurs, activists, academics, corporations, public agencies, and developers, MyData aims to empower individuals to give, deny, or revoke their consent to share data based on a clear understanding of why, how, and for how long their data will be used. Likewise, software companies played a key role in embedding accountability in the adoption of GDPR in Europe. Making it possible for companies to easily buy GDPR-compliant data management software accelerated uptake of the new data protection regulations and, for the largest companies, enabled them to set their global data systems to standards set by GDPR.
There is no ideal approach for participatory data governance mechanisms. They adapt to the situations for which they are developed to enable accountability in national, local, or community contexts. However limited or expansive a particular participatory mechanism may be, they all provide important complements to formal governance mechanisms by shifting power to affected communities and creating pathways for accountability.
|
Box 4. Types of participatory data governance mechanisms Recent years have witnessed an evolution in thinking and experimentation with mechanisms that shift power to data subjects and affected communities by enabling people to participate or have their interests represented in data governance. 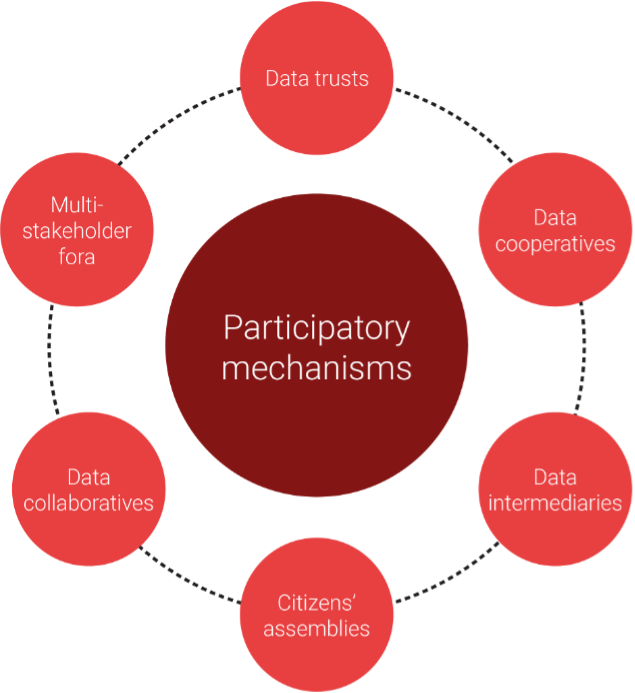
The World Bank refers to these as multi-stakeholder governance mechanisms, which they define as “participatory solutions which enable trust, value and equity in data use by adopting an approach that is informed by all people.”[cxxiii]The Open Data Institute has explored the concept of data institutions, or “organizations that steward data on behalf of others.”[cxxiv] Data institutions are a broad category that includes traditional organizations such as NSOs and newer constructs that enable greater participation through data trusts and data cooperatives. Data trusts and data cooperatives are legal entities with statutes, rules, or mandates.[cxxv], [cxxvi] They foster the emergence of trustworthy data practices by establishing structures where delegation and accountability mechanisms empower data subjects and affected communities that are not directly involved in daily decision making. Data intermediaries are structures or organizations that facilitate the exchange of information between data rights holders (such as people or businesses) by “encapsulating, communicating and enacting the shared interests of the relevant parties and safeguarding their interests.”[cxxvii] Some data intermediaries offer technology-based solutions for data sharing that ensure decision making power remains entirely in the hands of data subjects. In other cases, data intermediaries assume decision making, including on behalf of people. Multi-stakeholder fora, citizens’ juries, and assemblies aim to convene stakeholders with diverse and sometimes divergent interests around data to reach an agreement which is accepted by all stakeholders. They lead to the establishment of more trustworthy data practices by offering methods for building consensus and resolving conflicts and they tend to be more informal in nature. The New York Data Assembly and Data Collaboratives are examples of initiatives that balance individual and collective as well as public and private interests around data sharing and use.[cxxviii], [cxxix] What these all have in common is they create space to broaden participation in data governance by bringing interested and affected people together or creating a binding requirement to represent those who are most affected by data governance decisions. |
3.3 Accountability in practice
If increasing participation is the gold standard in responsive and accountable data governance, then we’d be remiss not to also confront the challenges and enablers inherent to it. Numerous examples make it clear that participatory governance is not only possible but already widespread, even in low-capacity settings. Challenges and enablers will be context-specific. Nonetheless, organizations aiming to increase participation will often face similar trade-offs related to practical constraints and balancing individual and collective interests, as this section describes.
First, pure democracy is messy and complex. It’s a relatively simple task to gather three people together to create an agreement for how to manage and use their data. But these are not the situations where participatory governance presents a challenge. Instead, most governance questions arise at national, regional, and international levels, creating a trade-off between the possibility for direct involvement in decision making and the number of people who can be directly consulted. In such cases, individuals and communities can delegate to a representative who can advance their interests and participate in decision making on their behalf. However, this approach is also replete with the challenges of tokenism and the generalization of the views of a complex community.
To avoid tokenism, participatory mechanisms must respect the inherent diversity of views within communities, understanding that people have different priorities."
This diversity of views, however, might fail to emerge even when participatory mechanisms are well-conceived as communities have internal power dynamics that disempower some members or leaders who privilege their own personal interests ahead of collective needs. Furthermore, participatory data governance approaches can be time and resource-intensive and are often at odds with the pace of project implementation and technological innovation.
Second, we should not expect people who have been historically marginalized and disempowered to have the same values, priorities, or resources for data governance as the people and institutions that currently hold power.[cxxx]Additionally, people who have faced marginalization might be disillusioned and skeptical about what is achievable by engaging in initiatives launched by those who have power. If powerful players consistently set the agenda and define the rules of engagement for participatory initiatives, buy-in from marginalized communities may be low.
Within the Indigenous peoples’ data rights movement, for example, the emphasis has been on data sovereignty and self-determination, framing agency, privacy, and data sharing as issues of community—not personal—power and autonomy.[cxxxi], [cxxxii] Where the focus is on addressing historical oppression, the balance between individual and collective rights in questions of data governance must be resolved through thoughtful participatory processes. Consultations must also highlight the resilience and strengths of communities—not only their needs and obstacles. Underpinning all of this is a critical question: How do we engage people in ways that address power asymmetries when the organizations and governments collecting data often have immense power and resources relative to local communities?
Finally, in seeking to increase participation in data governance, we must consider how to ensure that people have the knowledge, skills, abilities, resources, time, and willingness to take part in these processes. Certain forms of participatory data governance (i.e. those involving direct representation) require higher levels of engagement, knowledge, and skills than others (for instance, those involving delegation). Not all individuals need to become data experts. However, a general increase in levels of data literacy in society is desirable to enable participatory data governance mechanisms to flourish. Research shows that people at all levels of decision making have lower-than-necessary levels of data literacy, and that individuals may be unaware of the need, or unwilling to invest time, in protecting their own data.[cxxxiii] Although interest in personal data governance appears to be increasing, there is still a general lack of awareness and knowledge of data governance as it appears at local, organizational, and international levels, making it unlikely that participants will come to the table fully prepared to participate without investment in training and education.[cxxxiv],[cxxxv],[cxxxvi]Data governance institutions can also do more to make processes accessible and understandable for non-experts. We must also consider how to compensate people fairly for their time and insights to ensure that participatory processes do not further exacerbate inequalities.[cxxxvii] This includes avoiding subjecting people to repetitive and costly requests for information.
There are limits to the extent to which people can genuinely participate in data governance and to what can be achieved through participation. These constraints notwithstanding, in places where formal data governance mechanisms are fragmented or weak, participatory approaches can lead to the adoption of more trustworthy data practices and increase accountability in how public and private institutions and organizations collect and manage data. We can enable people to engage by providing tangible resources such as compensation or childcare at meetings to ensure that parents can attend. The goal is to adopt approaches that challenge the status quo and force us to question underlying assumptions about who has a say and what matters in data governance.
Creating true participation in data governance is only possible through intentional, well-planned, and flexible efforts."
Creating avenues for participation must also account for and balance complex community dynamics and the day-to-day constraints that may hold people back from getting involved. It is also critical to manage expectations by creating the space for meaningful contributions while being transparent about the limitations and practicalities of projects and organizations. Above all else, participatory mechanisms must protect people and not put them at risk.
Institutions and individuals charged with stewarding data have an important role to play in engaging with communities and adopting or developing participatory approaches to data governance. Data stewards are uniquely positioned to consider how formal and participatory mechanisms of data governance may interact to foster greater trust and accountability in decision making around data.
For accountability to work, rules need to be enforced, decisions and actions need to be inclusive and transparent, and people need to be able to verify that those in power are doing what they said they would do. This requires robust data governance that is built on a solid foundation of laws, policies, and institutions and is buttressed by participatory mechanisms that allow affected communities to be informed and have a say in how their data will be managed and used. When accountability is continuous, data governance becomes more trustworthy. Numerous examples of this exist already in both the policy and development spheres. Nonetheless, there is a need to continue to create space for more innovation and experimentation to improve participatory approaches to data governance. New and evolving models are needed to push the boundaries of what participatory mechanisms look like and to broaden the range of participants.
As data transforms society, all people, especially those who have been marginalized, should have the means to hold the powerful accountable for decisions that determine how their data can be managed and used."
4. Data in action
- The potential of data to change development outcomes and ultimately redress power imbalances lies in its effective use to inform decision making and produce fairer policies.
- Sustained data use by decision makers is not a given. Technical barriers to data use receive a lot of attention, but human and relational factors have a more significant impact on whether and to what extent data is used to its full potential.
- People’s ability and willingness to find common ground and work in partnership is instrumental to enhancing data use and building trust.
- Equipping people with the skills to understand, analyze, and use data is essential to increasing data use for public benefit.
Data is ubiquitous in today’s world, embedded in the social, cultural, and political contexts of every country in the world. Humans have never produced so much information so quickly, but increases in the quantity of data has not translated equally into our ability to address collective challenges. A wide range of incentives determine whether decision makers seek out data or willfully ignore or manipulate it. Ensuring that data is used is a complex business. Data is only one of several inputs when making a decision. This section focuses on the factors influencing whether decision-makers seek out data and use it in the public interest. This is important because, almost a decade after the publication of A World That Counts, much valuable data remains untapped and underutilized.[cxxxviii] This failure fuels bad policy and inefficient programs, benefits the most powerful in society who profit by perpetuating the status quo, and leaves people who are marginalized behind.
Data that is collected with agency and governed with accountability must still be used effectively to drive actions that improve people’s lives. Collaboration and partnerships can help to deliver these outcomes. The uses and applications of different types of data (i.e. personal or non-personal, quantitative or qualitative, and publicly or privately held) vary and therefore require different levels of protection and openness. In recent years, the development community has adopted more nuanced approaches to data availability and data use, going beyond an “open by default” mentality and toward a culture of openness focusing on sharing and use of data in specific contexts to address specific challenges.
This is what happened in Togo during COVID-19-related shutdowns, when 138,000 people living in poverty received mobile cash transfers through their phones. No application process, survey, questionnaire, enumerator, or social worker was involved. Instead, four data-holding partners came together behind the scenes, using phone records, satellite data, and population data to develop MobileAid. MobileAid’s cash delivery program demonstrates that existing data can be shared and leveraged through innovative partnerships to make meaningful improvements in people’s lives. Putting data into action, while promoting agency and accountability, is an essential component of more equitable data systems.
4.1 Factors that impact data use
Evidence-based decision making requires high-quality, timely data to be accessible to decision makers. This involves wide-ranging technical considerations including methodology, standards, infrastructure, data interoperability, format, and more. Discourse in data for development has largely focused on these considerations. Human factors that impact data use such as people’s motivations, incentives, and opportunities to collaborate in addition to their capacity, skills, and institutional and organizational cultures and constraints receive much less attention although they appear to have greater influence on whether and to what extent data is used.[cxxxix] These human factors are more difficult and complex to identify and slower and trickier to fix. But, as the following sections demonstrate, they’re far from intractable.
4.1.1 Data use suffers amidst a landscape of declining trust
Trust is both an enabler and an outcome of data use."
For decision makers to use data, they must trust in its validity and reliability. Likewise, the public must be able to trust, not only in data themselves, but also in the credibility of the data producers and in public institutions and decision makers to put that data to use. A 2021 paper, Towards a Framework for Governing Data Innovation: Fostering Trust in the Use of Non-Traditional Data Sources in Statistics Production, highlights that “you cannot have trust in the usability of statistics if the data that underpin them are of poor quality and those producing them lack integrity.”[cxl] As discussed in the preceding chapter, building more trustworthy data practices starts with establishing participatory governance approaches, which should also provide a venue for people to hold decision makers accountable for effective data use, for instance, by monitoring how evidence is leveraged for public policies over time.
Yet all too often decision makers do not use data for public benefit. Data is often used in ways that concentrate power in the hands of the already powerful.[cxli] Ignoring data, using it to harm or surveil people without their consent, using it selectively or taking it out of context, or intentionally misrepresenting data to sway people’s opinions or mislead them are uses of data that disempower people. Data in public policy and private decision making is part of a larger landscape of ongoing social and political events and personal motivations and biases. Ensuring that timely, high-quality data exists and is accessible provides no guarantee that decision makers will use it to address inequalities.
Failure to use data and misuse of data have devastating results for communities—especially those that are marginalized—and for society at large. Misuse and ignorance of data leads to bad policy outcomes and results in declining levels of trust in public authorities. Failure to respond to peoples’ needs over time leads to disillusioned citizens who, in turn, increasingly mistrust their governments to use their data. The consequences of declining levels of trust have been particularly visible during the COVID-19 pandemic, as we’ve seen with the adoption of contact tracing apps, which suffered from limited popularity and buy-in.[cxlii]
The spread of misinformation is also a sign of a declining trust in official institutions. Initiatives like the CoronaVirusFacts Alliance provide independent fact checking aimed at rebuilding citizens’ trust in the context of what is now called an “infodemic.”[cxliii] However, these initiatives alone are insufficient to rebuild trust in institutions in the absence of better policy outcomes that demonstrate the benefits of putting data into action for all of society.
4.1.2 A patchy record of public use of privately held data
Public trust in responsible data use has become particularly important because the data landscape has shifted away from governments and toward private sector companies as the primary producers and holders of data. Box 5 reflects on the benefits of public access to privately held data.
The absence of strong frameworks for data sharing and protection between governments and companies erodes public confidence and use of data. The public is often only aware of data sharing and use by companies and governments when a scandal breaks. The revelation that Israeli cybersecurity company NSO Group had shared personal data with governments who spied on citizens around the world is one example of this.[cxliv] Scandals erode public confidence in the public sector's ability to responsibly use and manage personal data, and they increase skepticism among policy makers about the benefits of sharing and using data from the private sector.
It doesn’t have to be this way, as many examples of public-private data-sharing partnerships born during the pandemic demonstrate. In one example, when the government of Argentina issued a call for data and analysis to respond to COVID-19, Telefonica Argentina responded by collaborating with the National University of San Martín to create a hub with up-to-date mobility data. “Privacy by design” to protect users' data was a critical feature of the program.[cxlv]The company signed agreements with national and local government agencies that used the hub on an ongoing basis to make policy decisions.[cxlvi]
|
Box 5. The benefits of public access to privately held data Large companies today have access to more and better data on people compared to many governments. Expanding the state’s access to privately held data is complicated, but it is seen as essential for many governments given the volume and reach of privately held data.[cxlvii] Yet sufficient legal and regulatory frameworks for accessing privately held data may not exist, and the public may not trust either side with their personal data. Meanwhile, governments are frequently excluded from accessing information that is largely available to other players based on pay-for-data solutions. Mobile Network Operators, for instance, sell customers’ aggregated and anonymized data to companies in finance, tourism, and retail that are willing to pay for insights. This problem can’t be resolved simply by asking governments to buy data from companies. Nor can it be solved by companies universally giving customers’ data away for free. Initiatives like the recent European Commission’s Data Act are new attempts to redress the balance between public and private sectors by granting public authorities access to privately held datasets (and prescribing the circumstances under which such access is required) by law, while establishing safeguards against misuse of data by the public sector.[cxlviii] There is no one-size-fits-all approach for data sharing, but a useful menu of options around access to privately held data is starting to develop. This includes regulatory measures, contractual partnerships, procurement solutions, reciprocity models, and more. Such approaches hold promise to align incentives and allow governments to safely access and use privately held data. |
4.1.3 Human interoperability and partnerships as important parts of the puzzle
Effective data use requires human interoperability—the idea that data doesn’t come together on its own but requires people working together across different parts of government, sectors, and communities.[cxlix] Individuals, not platforms or technical data pipelines, are at the heart of data sharing and use. At the most basic level, breakdowns in communication and coordination can leave data untapped to address public challenges. Beyond data interoperability—the ability to join up and merge data without losing meaning or context—the people engaged in designing, providing, collecting, analyzing, interpreting, and using data are crucial factors in enabling data use that empowers people at the bottom.
At the organizational level, multi-stakeholder partnerships can foster human interoperability and address human barriers to data use, ultimately putting data into action. Numerous examples show how partnerships between governments, private sector, academia, non-governmental organizations, and citizens lead to more informed decisions and help embed sustained data use in local and national contexts. Such partnerships are beneficial for all stakeholders involved, from traditional data institutions like NSOs to citizens’ groups and private sector players.
This is what happened when stakeholders in Kenya’s agricultural sector agreed that the government lacked reliable information on food stocks to guide policy and action amid COVID-19. Farmers, grocers, producers, and other stakeholders worked with government officials across departments and companies including Microsoft and ESRI to create the Food Staples Dashboard to monitor prices and availability of food stocks. The information was used in the context of Kenya’s Food Security War Room with more than 50 partners from development agencies, civil society, international organizations, government, and the private sector. The project enabled government officials to respond to the impact of COVID-19 lockdowns on food insecurity by strengthening food supplies, targeting food distribution, providing accurate information to citizens and media, and communicating directly with producers and consumers.[cl]
Work to break down barriers to data use in Senegal is another powerful illustration of human interoperability and the impact of multi-stakeholder partnerships, outlined below in Box 6.
|
Box 6. Breaking down barriers to data use in Senegal by building human interoperability In Senegal, data use was stymied for years until an investment in human relationships and partnerships opened agricultural data for public use.[cli] Agricultural activities account for the majority of economic activity in Senegal. For years, the national agriculture ministry produced regular data on farmers in the country that wasn’t used by other government ministries or non-governmental organizations. Instead, individual ministries, development agencies, and civil society organizations produced datasets for their own use, often duplicating efforts and multiplying inconsistencies, which led to poor policy outcomes. Through the Agridata project, led by IPAR (Initiative Prospective Agricole et Rurale), a Senagalese think tank, and supported by Development Gateway, more than 50 agricultural data stakeholders from the public sector, private sector, and civil society came together to identify data sources and to build trust over more than two years. Only by working together to align interests and resolve conflicts over who had ownership of this data were stakeholders able to agree to a common data platform to inform better decision making. Establishing a partnership between these actors was the first essential step to increasing data use among relevant decision makers. |
4.1.4 Shifting organizational culture
Widespread shifts in organizational culture within governments, companies, and the nonprofit sector are needed to realize the potential of both public and private data use for public benefit.
The Open Data Institute (ODI) has created a useful model for breaking down attitudes that affect whether data is used to its maximum benefit by companies, communities, organizations, and governments. ODI’s Theory of Change, included in Figure 3, distinguishes between treating data like a precious and proprietary commodity (data hoarding) and shying away from data use altogether because of legitimate concerns of how it may be used or who has access to it (data fearing). In both scenarios, the power of data is left untapped without cultures “of openness and trust around data.”[clii]
Figure 3: ODI's theory of change
This is not simply letting good data go to waste. Poor data use cultures, especially within governments and companies, exacerbate power asymmetries and prevent the establishment of coalitions and partnerships.[cliii] When data is hoarded by organizations, its benefits go to the few instead of the many, and society cannot access its full value. Likewise, not collecting, analyzing, or using data out of fears of negative effects squanders the enormous potential of data—much of which already exists and is held by other actors. Only by transforming organizational culture, exploiting the power of partnerships, and holding leadership accountable can we fully unlock the power of data to affect positive social change.
4.2 Building data skills and literacy
People’s ability and confidence to understand, analyze, and make decisions about data, or data literacy, are the practical bedrocks of effective data use. Once seen as a technical concern for business leaders and public servants, the proliferation of data and software platforms has expanded data literacy concerns to the wider public sphere. Now, individuals across organizations and particularly in management roles must feel empowered to assess and make decisions based on data, and the broader public needs to develop the knowledge and confidence to hold decision makers accountable for data use. Building skills around data is central to increasing data use by individuals, organizations, and governments.[cliv],[clv]
People need to feel confident in their ability to engage with and think critically about data to hold decision makers accountable.[clvi] Increasing people’s engagement with and use of data is a two-way street. Not only do people need to see value in paying attention to data and official statistics, they must also be able to access and understand them. These are all factors that fall largely onto the shoulders of data producers who often communicate about data in ways that obfuscate its meaning and use. The onus is on these data producers to ensure the data is accessible, understandable, and usable. Data intermediaries and other organizations which stand in between data producers and data users can also help bridge the knowledge gap and increase participation in data decision making. A Nigerian civil society organization, BudgIT, offers a useful illustration of how increasing people’s understanding of and access to official data can shift power dynamics and increase government accountability, outlined in Box 7.
|
Box 7. Increasing transparency around public data use in Nigeria BudgIT launched in 2011 to make the federal budget more transparent to Nigerians by using simplified explanations and visual representations of data. BudgIT’s campaign reached 2.5 million people and engaged 25,000 people in the budget review process in 2017, leading to exposure of fraudulent projects and a cap on pay for civil servants. SDSN TReNDS authors note that this illustrates the ways in which “data openness, accessibility, and literacy can build trust in public institutions and improve efficiency in public spending.”[clvii] |
Data literacy should take a community-centered approach. Communities need to collectively care about the promise and the peril of data. Data literacy should enable communities to hold governments accountable and empower them to address problems in their own ways.
4.3 Data use for public benefit
While political challenges to data use are large and complex, in many cases, human and relational barriers are the biggest obstacles to effective data use. The factors that enable us to address these barriers are inevitably linked. A culture in which data is protected appropriately and shared openly requires trust, incentives, relationships, and new partnerships among stakeholders. Likewise, increasing people’s trust in governments and organizations’ responsible use of data requires accountability and transparency, enabled by building the public’s skills in data literacy and creating participatory mechanisms through which people can make decisions about how their data is used. None of these factors can be improved without the others, and all are key means of addressing power imbalances.
Data use is deeply embedded in our lives: We use data every day to make decisions about travel, work, shopping, education, and much more. At a larger scale, data gives decision makers immense power to take informed action for public benefit. To materialize these benefits, leaders and data stewards in the public and private sectors need to go beyond the mechanics of data access and sharing to create trust, build relationships and partnerships, invest in data skills, and create incentives to use data for good.
Conclusion and recommendations
Today’s data ecosystems are inextricably entwined with and too often reinforce power structures that exist in society resulting in inequitable distribution of the benefits of data.
The consensus emerging from the Data Values Project is to advocate for actions that will shift power to the people most affected by data production and use."
This requires a systematic change that promotes individual and collective agency, fosters accountable data governance, and ensures data is used for actions that improve well-being. This means that people are able to shape how they are included in data, to influence whether and how their data will be used, and to create a human-centered approach to ensuring data is used for social good. Shifting power requires respect, solidarity, accountability, introspection, and space to call out bad practices.[clviii],[clix] None of this requires sacrificing analytical rigor or statistical standards. Shifting power by bringing people’s views and experiences into data design, production, and use will improve its quality.
These changes are already happening in cities, organizations, and in statistical offices and other government ministries around the world, as the many examples in this paper (and in the accompanying annex) demonstrate. But, for most of us, the hard work of translating the ideas laid out in this paper into the real world starts now. Every organization that chooses to pursue a Data Values agenda will start from a different baseline. Incentives will vary and progress will necessarily be uneven. None of these changes will come without trade-offs, but consultations within the Data Values Project have shown over and over again that many people and organizations are already putting these ideas into action and have been doing so for some time. The stakes—of losing public trust in data and statistics and wasting opportunities to use data to increase prosperity and equitable growth—are too high to ignore.
Paradigm Initiative’s 'Gbenga Sesan argues that everyone should be a data activist: The data equity agenda concerns us all.[clx] It also requires investments of resources, time and capacities. As data and technology transform society, people must have the power to shape their digital futures; this cannot be an afterthought. Governments, civil society, international organizations, private companies, and donors each have a role to play in building a fair data future.
Data stewardship has emerged as a critical means to manage the challenges, opportunities, and risks of data-driven organizations and systems. National statistical offices are uniquely positioned to act as data stewards in the public sector, though stewardship may be performed by a person, a single entity, or a combination of people or organizations across public and private sectors.[clxi] [clxii] Data stewards are well-placed to consider the power imbalances that exist in data systems and have a unique role to play in promoting agency, accountability, and action. They can take on responsibility for building partnerships with civil society organizations and community groups, bringing together committees and task forces to examine exclusion and biases in data, establishing systems for upskilling staff and creating incentives for data use, and creating and advocating for participatory mechanisms of data governance.
5.1 Vision and recommendations
The Data Values Project envisions a world where people can be more equal players in the production and use of data that affects their lives. As this paper explains, agency in data, accountability in data governance, and putting data into action are essential to realizing this vision. The recommendations in this section set out ways that governments, donors, international agencies, civil society organizations, and private companies can work together to make this vision a reality.
5.1.1 Government departments and agencies
To achieve this vision, government departments and agencies establish mechanisms for civil society and communities to shape data collection processes and participate in decisions about how their data will be governed. Public officials and agencies communicate transparently about data laws, policies, and their implications and lead by example, allowing themselves to be held accountable and holding other powerful actors accountable for harmful data-related practices. They also invest in the frameworks, skills, and relationships that will drive sustained data use to reduce inequalities.
To get there, government departments and agencies, working with NSOs, should:

Agency in data |
|

Accountability in data governance |
|

Data in action |
|
5.1.2 Donors and international organizations
To achieve this vision, donors and international organizations accompany digital development efforts with financial and technical support for governments and organizations to foster inclusion and participation. They create and support mechanisms to listen to communities and establish feedback loops internally and in their assistance to governments and organizations. They recognize that digital development is not only about tools and products and they invest heavily in skills, capacity, and partnerships to build a culture of data use. They strive to share knowledge and align their priorities with national development plans, and they seek to complement existing initiatives rather than carrying out duplicative activities.
To get there, donors and international organizations should:
Agency in data |
|
Accountability in data governance |
|
Data in action |
|
5.1.3 Private companies
To achieve this vision, private companies are active contributors to a fair data future. They acknowledge the power they wield and take steps to promote more equitable societies that protect individual and community data rights. They engage in cross-sectoral partnerships, contribute data for social good, and establish user-centric and participatory approaches to build products and services that do not reinforce structural inequalities. They develop business practices, services, and products that align with people’s aspirations and values, are not extractive, and that empower people to shape how their data is used.
To get there, private companies should:
Agency in data |
|
Accountability in data governance |
|
|
Data in action |
|
5.1.4 Civil society organizations
To achieve this vision, civil society organizations represent communities’ needs, interests, and ideas by supporting their participation in data production and governance. They collect and share data from people and communities and use data to hold governments accountable for their responsiveness to communities. They play a dual role of partners to governments, donors, international organizations, private companies, and activists pushing for greater transparency and accountability in data production and use.
To get there, civil society organizations should:
Agency in data |
|
Accountability in data governance |
|
Data in action |
|
Taken together, these actions will contribute to a world in which people have power to shape how they are measured and represented in data. People who have historically been excluded from the levers of power will inform and hold decision makers accountable for using and managing personal data. People’s interests can be better represented in decisions about their data, which is used to address inequalities and promote social and economic well-being. Evidence-based decision and policy making that is grounded in robust data and is accountable to people drives sustainable development. This is the world the Data Values Project is working towards.
Acknowledgements
This white paper is based on contributions from 240 individuals from 145 organizations who contributed during a year-long consultation. A draft version of the paper was published in May 2022 for public consultation. In total, 355 individuals from 63 countries contributed, often more than once, to shaping the paper’s core messages and building the Data Values movement. We extend our gratitude to every individual who shared their insights, expertise, and valuable time. Written and recorded contributions can be found on the Data Values Project web hub.
The Data Values Project is coordinated by the Global Partnership for Sustainable Development Data (the Global Partnership) and led by the Global Partnership’s Technical Advisory Group (TAG) and Secretariat team. We appreciate the TAG’s intellectual leadership, contributions to the consultation, and stewardship of this white paper. We’re indebted to Joshua Powell who, as TAG Chair, contributed significantly to shaping this project and promoting wide engagement. We are particularly grateful to TAG members who led working groups through the consultation and to those who provided written feedback on earlier drafts of this paper including: Flo Albu, Grant Cameron, Rebecca Firth, Al Kags, John Kapp, Deepa Karthekeyan, Camilo Mendez, Juan Daniel Oviedo, Tom Orrell, Francesca Perucci, Frederic Pivetta, Joshua Powell, Steve Schwartz, Claudia Wells, and Karen Lizeth Chavez Quintero.
We are also grateful to Lysa John, Thobekile Matimbe, Aidan Peppin, Amelia Pittman, Carolina Rossini, and Ivette Yañez for taking the time to review an early draft of this white paper. Your feedback and insights have greatly strengthened this document.
This paper was drafted by Martina Barbero, Karen Bett, Janet McLaren, and Jenna Slotin. It was rigorously reviewed and shaped by Amy Leach, Claire Melamed, Jennifer Oldfield, and Kate Richards, with input from the Global Partnership Secretariat team. The paper was edited by Amy Leach, Janet McLaren, and Elizabeth Black. Translation of the summary of this document was done by Capital Linguists, LLC (French) and Alexandra Ferguson (Spanish). The full white paper was translated into Spanish and French using DeepL Translator, and the translated versions were reviewed and copyedited by Martina Barbero (French) and Fredy Rodriguez (Spanish).
References
[i] United Nations (2020) Roadmap for digital cooperation. United Nations [online]. Available at: https://www.un.org/en/content/digital-cooperation-roadmap/assets/pdf/Roadmap_for_Digital_Cooperation_EN.pdf
[ii] Open Data Watch and Data2X (2019) Bridging the gap: mapping gender data availability in Africa. Open Data Watch [online]. Available at: https://data2x.org/resource-center/bridging-the-gap-mapping-gender-data-availability-in-africa/; Thinayane, M. and Christine, D. (2021) Dimensioning data marginalization: social indicators monitoring, Development, 64 (March), pp. 119–128. Available at: https://doi.org/10.1057/s41301-021-00284-2
[iii] AidData (2017) Avoiding data graveyards: insights from data producers & users in three countries. Williamsburg, Va.: AidData at William & Mary.
[iv] The World Bank (2021) World development report 2021: data for better lives. The World Bank [online]. https://www.worldbank.org/en/publication/wdr2021
[v] Anderson, B. and Sabiti, B. (2022) Data disharmony: How can donors better act on their commitments?. Development Initiatives [online]. Available at: https://www.devinit.org/resources/data-disharmony-how-can-donors-better-act-on-their-commitments/
[vi] For example: Heaven, W. (2020) Predictive policing algorithms are racist. They need to be dismantled. MIT Technology Review 2020 (July). Available at: https://www.technologyreview.com/2020/07/17/1005396/predictive-policing-algorithms-racist-dismantled-machine-learning-bias-criminal-justice/
[vii] United Nations, Roadmap for digital cooperation.
[viii] PARIS21 (2021) Partner Report on Support to Statistics (PRESS 2021). Partnership in Statistics for Development in the 21st Century[online]. Available at: http://paris21.org/press2021
[ix] Powell, J. (2021) How data is adding to the unfolding crisis in Afghanistan. The Data Values Digest, 20 August. Available at: https://datavaluesdigest.substack.com/p/how-data-is-adding-to-the-unfolding?s=w
[x] Slotin, J. and McLaren, J. (2022) Fighting cybercrime in the humanitarian and development sectors. The Data Values Digest, 14 February. Available at: https://datavaluesdigest.substack.com/p/fighting-cybercrime-in-the-humanitarian?s=w
[xi] Reporting by the New York Times, the Guardian and Channel 4 uncovered Cambridge Analytica’s efforts to sway elections in prior years following the news of Meta’s data sharing in 2018. See: Cadwalladr, C. (2018) Cambridge Analytica's ruthless bid to sway the vote in Nigeria, The Guardian, 21 March. Available at: https://www.theguardian.com/uk-news/2018/mar/21/cambridge-analyticas-ruthless-bid-to-sway-the-vote-in-nigeria; Channel 4 News (2018) Data, democracy and dirty tricks, 19 March. Available at: https://www.channel4.com/news/data-democracy-and-dirty-tricks-cambridge-analytica-uncovered-investigation-expose
[xii] Human Rights Watch News (2021) UN shared Rohingya data without informed consent: Bangladesh provided Myanmar information that refugee agency collected, 15 June. Available at: https://www.hrw.org/news/2021/06/15/un-shared-rohingya-data-without-informed-consent#
[xiii] United Nations (2022) Secretary-General urges action to extinguish ‘five-alarm global fire’, as he presents annual report on United Nations work, priorities for 2022 in General Assembly, 21 January. Available at: https://www.un.org/press/en/2022/ga12401.doc.htm
[xiv]CIGI-Ipsos (2019) CIGI-Ipsos global survey on internet security and trust, CIGI-Ipsos [online]. Available at: https://www.ipsos.com/en/2019-cigi-ipsos-global-survey-internet-security-and-trust; Electronic Privacy Information Center (EPIC) (n.d.) Public opinion on privacy. Available at:https://archive.epic.org/privacy/survey/
[xv] CIVICUS (2021) Global press release: 13 countries downgraded in new ratings report as civic rights deteriorate globally, 8 December. Available at: https://findings2021.monitor.civicus.org/rating-changes.html#global-press-release
[xvi] Roberts, T. (2021) Digital rights in closing civic space: lessons from ten African Countries, Brighton: Institute of Development Studies [online]. Available at: DOI: 10.19088/IDS.2021.003
[xvii] Civil Society Collaborative on Inclusive COVID-19 Data (2021) An unequal pandemic: insights and evidence from communities and civil society organizations. Global Partnership for Sustainable Development Data (GPSDD) [online]. Available at: https://www.data4sdgs.org/sites/default/files/file_uploads/UnequalPandemic_FINAL_spreads min.pdf
[xviii] Van Ness, L. (2021) For states’ COVID contact tracing apps, privacy tops utility, Pew Trusts, 19 March. Available at: https://www.pewtrusts.org/en/research-and-analysis/blogs/stateline/2021/03/19/for-states-covid-contact-tracing-apps-privacy-tops-utility
[xix] Altshuler, T. and Hershkowitz, R. (2020) How Israel’s COVID-19 mass surveillance operation works, Brookings: TechStream. Available at: https://www.brookings.edu/techstream/how-israels-covid-19-mass-surveillance-operation-works/
[xx] The need for better data to measure the newly-minted Sustainable Development Goals was expressed by the UN’s High Level Panel on the Post-2015 Development Agenda and echoed in the report, “A World that Counts,” launching what became known as the “data revolution” in the post-Millenium Development Goals era. See: Data Revolution Group (201-) What is the ‘data revolution.’ Available at: https://www.undatarevolution.org/data-revolution/; Independent Expert Advisory Group (IEAG) (2014) A world that counts: mobilising the data revolution for sustainable development. United Nations, Data Revolution Group [online]. Available at: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&ved=2ahUKEwiCmoG81dL4AhVsVfEDHbtCC1QQFnoECAYQAQ&url=https%3A%2F%2Fwww.undatarevolution.org%2Fwp-content%2Fuploads%2F2014%2F11%2FA-World-That-Counts.pdf&usg=AOvVaw1265cxmd1C3-atQCHDlfAK.
[xxi]Serajuddin, U., Uematsu, H., Wieser, C., Yoshida, N. and Dabalen, A. (2015) Data deprivation: another deprivation to end (WB 7252-2015). Washington, DC: World Bank [online]. https://openknowledge.worldbank.org/handle/10986/21867
[xxii] Espey, J. (2021) Data stewardship and the role of NSOs in the changing data landscape, United Nations Statistical Commission: 52nd Session (2021). Online, 10 February 2021. Available at: https://unstats.un.org/unsd/statcom/52nd-session/side-events/20210210-1M-data-stewardship-and-the-role-of-NSOs-in-the-changing-data-landscape
[xxiii] UN Secretary General (2020) Data strategy of the secretary-general for action by everyone, everywhere with insight, impact and integrity 2020-22. United Nations [online]. Available at: https://www.un.org/en/content/datastrategy/index.shtml
[xxiv] Collaborative on Inclusive COVID-19 Data, An unequal pandemic.
[xxv] OECD (2021) Development co-operation report 2021: shaping a just digital transformation. Paris: OECD Publishing. Avilable at: https://doi.org/10.1787/ce08832f-en
[xxvi] Open Data Watch and Data2X, Bridging the gap.
[xxvii] Thiyane and Christine, Dimensioning Data Marginalization.
[xxviii] AidData, Avoiding data graveyards.
[xxix] The World Bank, World development report 2021.
[xxx] Anderson and Sabiti, Data disharmony.
[xxxi] Heaven, Predictive policing algorithms are racist.
[xxxii] Berdou, E., Bligh, L., Currie, C., Hepworth, C., and Perry, C. (2021) Evaluation of the Global Partnership for Sustainable Development Data. ITAD [online]. Available at: https://www.data4sdgs.org/itad-evaluation
[xxxiii] United Nations, Roadmap for digital cooperation.
[xxxiv] Although data is produced through processes that reflect existing societal structures, statistical standards and quality frameworks developed by international and national bodies exist to preserve the objectivity of statistical processes, definitions, and practices.
[xxxv] The World Bank, World development report 2021.
[xxxvi] D’Ignazio, C. and Klein, L. (2020) ‘The power chapter,’ in Data Feminism. MIT Press [online]. Available at: https://data-feminism.mitpress.mit.edu/pub/vi8obxh7/release/4
[xxxvii] Ada Lovelace Institute (2021) Participatory data stewardship. Ada Lovelace Institute [online]. Available at: https://www.adalovelaceinstitute.org/report/participatory-data-stewardship/
[xxxviii] Berdou, E. (2016) The question of inclusiveness, Making All Voices Count [online]. Available at: https://www.makingallvoicescount.org/publication/all/
[xxxix] UN Statistics Division (2021) The Data Values Project - redefining what it means to live in a digital society [Panel discussion]. Third UN World Data Forum, Bern, Switzerland, 18(?) October. Available at: https://www.youtube.com/watch?v=E3IefXqLMPk
[xl] See for example methodological guidelines developed by the UN Statistics Division on statistical classification: United Nations Statistics Division (UNSD) (n.d.) Statistical Classifications. Available at: https://unstats.un.org/unsd/classifications/; and on quality assurance: United Nations Statistics Division (UNSD) (n.d.) Methodology: Quality Assurance. Available at: https://unstats.un.org/unsd/methodology/dataquality/
[xli] Global Partnership for Sustainable Development Data: Phillips, G. and Orrell, T. (2021) We are here! - #DataValues fireside chats. 10 August. Available at: https://www.youtube.com/watch?v=_ojbnGrE7-A&list=PLi5qXhh-ze8Cz2J_h86sKcp1BCN9gZ74r&index=2&t=45s
[xlii] Slotin, J. (2021) Why are we measuring assimilation?, Data Values Digest, 20 August. https://datavaluesdigest.substack.com/p/why-are-we-measuring-assimilation?s=r
[xliii] Arora, A. (2021) Key remarks from the chief statistician of Canada [Speech]. The Data Values Project - Reimagining how we unlock the value of data for all.
[xliv] Slotin, J. and McLaren, J. (2021) Exploring routes individual and collective data agency, Global Partnership for Sustainable Development Data, 13 September. Available at: https://www.data4sdgs.org/news/exploring-routes-individual-and-collective-data-agency
[xlv] Paradigm Initiative (2021) COVID-19 and Digital Right: A compendium on health surveillance stories in Africa, Paradigm Initiative [online]. Available at: https://paradigmhq.org/report/covid-19-and-digital-rights-a-compendium-on-health-surveillance-stories-in-africa/
[xlvi] Tisné, M. (2020) The data delusion, Luminate [online]. Available at: https://luminategroup.com/posts/report/the-data-delusion
[xlvii]UN Sustainable Development Group (UNSDG) (2022?) Leave no one behind. Available at: https://unsdg.un.org/2030-agenda/universal-values/leave-no-one-behind
[xlviii]Open Data Watch (2017) Better data improves women’s lives, Data Impacts Case Studies [online]. Available at: https://dataimpacts.org/project/health-surveys/
[xlix] Thiyane and Christine, Dimensioning data marginalization.
[l] The Ruff Institute of Global Homelessness (2022) A place to call home. Available at: https://ighomelessness.org/category/a-place-to-call-home/(Accessed: 6 April 2022).
[li] Thiyane and Christine, Dimensioning data marginalization.
[lii] Data Values Project Focus Group Discussion 1 (2021) What does genuine inclusion through data look like and how do we make this a standard practice?, 14 October.
[liii] Kenya Revenue Authority. (n.d.) Social media posts inspiring tax compliance says KRA, Kenya Revenue Authority [online]. Available at: https://kra.go.ke/en/media-center/news/1506-social-media-posts-inspiring-tax-compliance-says-kra
[liv] Taylor, L. (2017) What is data justice? The case for connecting digital rights and freedoms globally, Big Data and Society, 4(2), pp. 1-14. Available at: https://journals.sagepub.com/doi/10.1177/2053951717736335
[lv] Schoemaker, E., Currion, P., and Pon B. (2018) Identity at the margins: identification systems for refugees. Caribou Digital [online]. Available at: https://assets.publishing.service.gov.uk/media/5cecedd6ed915d2475aca8c5/Identity-At-The-Margins-Identification-Systems-for-Refugees.pdf
[lvi] United Nations Statistics Division (2014) Fundamental principles of official statistics. Available at: https://unstats.un.org/unsd/dnss/gp/fundprinciples.aspx
[lvii]Monroe, J. (2022) Woke up this morning to the radio talking about the cost of living rising a further 5%. It infuriates me the index that they use for this calculation, which grossly underestimates the real cost of inflation as it happens to people with the least. Allow me to briefly explain. [cont.] [Twitter] 19 January. Available at: https://twitter.com/BootstrapCook/status/1483778776697909252?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E1483778776697909252%7Ctwgr%5E%7Ctwcon%5Es1_&ref_url=https%3A%2F%2Fwww.data4sdgs.org%2Fnews%2Fspaghetti-and-statistics-measuring-real-cost-living
[lviii]Melamed, C. (2022) Spaghetti and statistics: measuring the real cost of living, Global Partnership for Sustainable Development Data, 28 January. Available at: https://www.data4sdgs.org/news/spaghetti-and-statistics-measuring-real-cost-living
[lix]Hardie, M. (2022) Measuring the changing prices and costs faced by households, National Statistical, 26 January. Available at: https://blog.ons.gov.uk/2022/01/26/measuring-the-changing-prices-and-costs-faced-by-households/
[lx] Federal Trade Commission (FTC) (2014) Data brokers: a call for transparency and accountability, Federal Trade Commission [online]. Available at: https://www.ftc.gov/system/files/documents/reports/data-brokers-call-transparency-accountability-report-federal-trade-commission-may-2014/140527databrokerreport.pdf
[lxi]Angwin, J., Larson, J., Mattu, S., Kirchner, L. and ProPublica (2016) Machine bias, ProPublica, 23 May. Available at: https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
[lxii] Center for Policing Equity (2019) Using data science to eliminate racial bias in policing, The Audacious Project. Available at: https://www.audaciousproject.org/grantees/center-for-policing-equity
[lxiii]IDRC | CRDI: Kassam, N. (2017) The importance of registering births, marriages and deaths. 12 September. Available at: https://www.youtube.com/watch?v=8yCkllVhL2M
[lxiv] Oviedo, J., Fenz, K., Fonteneau, F., and Riedl, S. (2021) Can national statistical offices shape the data revolution?, Brookings, 3 September. Available at: https://www.brookings.edu/blog/future-development/2021/09/03/can-national-statistical-offices-shape-the-data-revolution/
[lxv] Fraym (2021) Mapping populations for vaccine equity. Available at: https://fraym.io/mapping-vaccine-equity/.
[lxvi] The Global Partnership for Sustainable Development Data (2021) Inclusive design principles, 12 July. Available at: https://www.data4sdgs.org/index.php/resources/five-inclusive-design-principles
[lxvii]Oxford Poverty and Human Development Initiative (2018) Global multidimensional poverty index. Available at: https://ophi.org.uk/multidimensional-poverty-index/
[lxviii] Oxford Poverty and Human Development Initiative (2021) Global multidimensional poverty index 2021. Available at: https://ophi.org.uk/global-mpi-2021/
[lxix] Monson, A. (2021) Tracking gender equality with data: the 2022 SDG Gender Index, Tableau, 21 March. Available at: https://www.tableau.com/about/blog/2022/3/tracking-gender-equality-data-2022-sdg-gender-index.
[lxx] United Nations Secretariat, Department of Economic and Social Affairs, Statistics Division (2021) Eighth global forum on gender statistics, Global Forum on Gender Statistics. Online, 30 September – 1 October 2021, 1-12. Available at: https://unstats.un.org/unsd/demographic-social/genderstat-forum-8/Report%20of%208th%20GFGS_2021_FINAL.pdf
[lxxi]Statistics Canada (2021) Disaggregated data action plan: why it matters to you, 8 December. Available at: https://www150.statcan.gc.ca/n1/pub/11-627-m/11-627-m2021092-eng.htm
[lxxii] Poverty and Human Development Agency (PHDMA) (n.d.) Voice of PHDMA. Available at: http://phdma.odisha.gov.in/node/22
[lxxiii] The Centre for Internet and Society and the Domestic Workers Rights Union (2021) Platforms, power, and politics: perspectives from domestic and care work in India. The Centre for Internet and Society. Available at: https://cis-india.org/raw/platforms-power-and-politics-perspectives-from-domestic-and-care-work-in-india
[lxxiv] Chisaka, T. (2021) Five tips to promote data inclusivity, Data Values Project, 23 July. Available at: https://www.data4sdgs.org/news/five-tips-promote-data-inclusivity
[lxxv] Innovation to Inclusion (2021) Advocacy learning document. Leonard Chesire [online]. Available at: https://www.leonardcheshire.org/sites/default/files/2021-12/i2i-advocacy-learning-aw-accessible.pdf
[lxxvi][lxxvi] United Nations Population Fund (2016) Census reaches vulnerable women and girls in a remote area of Myanmar for the very first time, United Nations Population Fund, 12 April. Available at: https://www.unfpa.org/news/census-reaches-vulnerable-women-and-girls-remote-area-myanmar-very-first-time
[lxxvii]The World Bank, World development report 2021.
[lxxviii] The Danish Institute for Human Rights (2021) Promoting and protecting human rights annual report 2020-21. The Danish Institute for Human Rights [online]. Available at: https://www.humanrights.dk/result/bringing-human-rights-defenders-official-statistics
[lxxix] The Open Institute (2017) #DataWork: from the abstract to the reality, The Open Institute, 18 July. Available at: https://openinstitute.africa/datawork-from-the-abstract-to-the-reality/
[lxxx] Leonard Cheshire (2020) CitizEMPOWER: the importance of supporting inclusive citizen-generated data initiatives, Medium, 15 October. Available at: https://leonard-cheshire.medium.com/citizempower-the-importance-of-supporting-inclusive-citizen-generated-data-initiatives-8b81e78ebe2
[lxxxi] United Nations Statistics Division (UNSD) (n.d.) Methodology: City Groups. Available at: https://unstats.un.org/unsd/methodology/citygroups/
[lxxxii] BBC (2019) Kenya census to include male, female and intersex citizen, BBC News, 26 July. Available at: https://www.bbc.com/news/world-africa-49127555
[lxxxiii] Shearer, E. (2020) The dividing line: how we represent race in data, Open Data Institute, 26 October. Available at: https://theodi.org/article/the-dividing-line-how-we-represent-race-in-data/
[lxxxiv] Humanitarian OpenStreetMap Team (202-) HOT is an international team dedicated to humanitarian action and community development through open mapping. Available at: https://www.hotosm.org/
[lxxxv] The Data Assemblies (202-) The Data Assemblies. Available at: https://thedataassembly.org/
[lxxxvi]Ada Lovelace Institute, Participatory data stewardship.
[lxxxvii] Agüero, F. (2016) How more accurate census data can shape social justice in Colombia and Peru, Ford Foundation, 23 March. Available at: https://www.fordfoundation.org/news-and-stories/stories/posts/how-more-accurate-census-data-can-shape-social-justice-in-colombia-and-peru/
[lxxxviii]Conferencia Nal de Organizaciones Afrocolombianas (2015) Cuéntame - Yo cuento en este cuento - CNOA. 25 March. Available at: https://www.youtube.com/watch?v=vVEiG9qrrzU
[lxxxix] Azcárate, F. (2019) ¿Qué falló en el polémico censo del 2018? Responde el director del Dane, El Pais, 14 July. Available at: https://www.elpais.com.co/economia/que-fallo-en-el-polemico-censo-del-2018-responde-el-director-del-dane.html
[xc]Oviedo, Fenz, Fonteneau, and Riedl, National statistical offices.
[xci] For more on the Colombian statistics agencies use of experimental statistics, see: DANE (n.d.) Estadísticas experimentales. Available at: https://www.dane.gov.co/index.php/en/estadisticas-por-tema/estadisticas-experimentales
[xcii] United Nations Economic and Social Council (2021) Report of the working group on data stewardship. United Nations Economic and Social Council [online]. Available at: https://unstats.un.org/unsd/statcom/53rd-session/documents/2022-5-DataStewardship-E.pdf
[xciii] Govlab (2020) (Re-)defining the roles and responsibilities of data stewards for an age of data collaboration. Govlab [online]. Available at: https://thegovlab.org/static/files/publications/wanted-data-stewards.pdf
[xciv] Ada Lovelace Institute (2021) Disambiguating data stewardship. Ada Lovelace Institute [online]. Available at: https://www.adalovelaceinstitute.org/blog/disambiguating-data-stewardship/
[xcv]Global Partnership for Sustainable Development Data (GPSDD) (2021) Why we should all be activists - #DataValues fireside chats. 9 November. Available at: https://www.youtube.com/watch?v=jPyJquA4c9M
[xcvi] Miller K. (2021) Radical proposal: data cooperatives could give us more power over our data, Stanford University Human-Centered Artificial Intelligence, 20 October. Available at: https://hai.stanford.edu/news/radical-proposal-data-cooperatives-could-give-us-more-power-over-our-data
[xcvii] Foxglove (2021) Success! UK government concedes lawsuit over £23m NHS ‘data deal’ with controversial US tech corporation Palantir, 1 April. Available at: https://www.foxglove.org.uk/2021/04/01/success-uk-government-concedes-lawsuit-over-23m-nhs-data-deal-with-controversial-us-tech-corporation-palantir/
[xcviii] Lomas, N., (2021) UK class action-style suit filed over DeepMind NHS health data scandal, TechCrunch, 30 September. Available at:https://techcrunch.com/2021/09/30/uk-class-action-style-suit-filed-over-deepmind-nhs-health-data-scandal/
[xcix] Banner, N., (2020) A new approach to decisions about data, Understanding Patient Data, 8 July. Available at:https://understandingpatientdata.org.uk/news/new-approach-decisions-about-data
[c] Pisa, M., Dixon, P., Ndulu, B., and Nwankwo, U. (2020) Governing data for development: trends, challenges, and opportunities. Washington, DC: Center for Global Development. https://www.cgdev.org/sites/default/files/governing-data-development-trends-challenges-and-opportunities.pdf
[ci] The World Bank, World Development Report 2021.
[cii]Greenleaf, G. and Bertil, C. (2020) 2020 ends a decade of 62 new data privacy laws, Privacy Laws & Business International Report, 163 (2020), pp. 24-26. Available at: https://ssrn.com/abstract=3572611
[ciii] Pisa, M. and Nwankwo, U. (2021) Are current models of data protection fit for purpose? Understanding the consequences for economic development, Center for Global Development, 9 August. Available at: https://www.cgdev.org/publication/are-current-models-data-protection-fit-purpose-understanding-consequences-economic
[civ] The World Bank, World Development Report 2021.
[cv] Medine, D. (2021) Data protection: consent is dead (long live privacy), Center for Global Development, 25 February. Available at: https://www.cgdev.org/blog/data-protection-consent-dead-long-live-privacy
[cvi]Kon, G. (circa. 2017) Does anyone read privacy notices? The facts, Linklaters. Available at: https://www.linklaters.com/en/insights/blogs/digilinks/does-anyone-read-privacy-notices-the-facts
[cvii]Tisne, M. (2020) The Data Delusion: protecting individual data isn’t enough when the harm is collective. Luminate. Available at: https://luminategroup.com/storage/1023/The-Data-Delusion---July-2020.pdf
[cviii] Tisne, The Data Delusion.
[cix]Viljoen, S. (2020) A relational theory of data governance, Yale Law Journal, 131 (November). Available at: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3727562
[cx] Tennison, Jeni. (2020) Community consent, Jenitennison.com, 17 January. Available at: http://www.jenitennison.com/2020/01/17/community-consent.html
[cxi] Ada Lovelace Institute, Participatory data stewardship.
[cxii] Arnstein, S. (1969) A ladder of citizen participation, Journal of the American Institute of Planners, 35(4), pp. 216-224. Available at: https://www.tandfonline.com/doi/abs/10.1080/01944366908977225
[cxiii] Regulation (EU) of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data (General Data Protection Regulation) (S.I. No. 679/2016). Brussels: European Union. Available at: https://eur-lex.europa.eu/eli/reg/2016/679/oj
[cxiv] The legal data protection framework of Uruguay is composed of three main texts: The Data Protection Act (Decree 18.331/2008) [in Spanish]. Available at: https://www.impo.com.uy/bases/leyes/18331-2008; Reglamentacion de la ley 18.331, relativo a la proteccion de datos personales (S.I. no. 414/009) [in Spanish]. Available at: https://www.impo.com.uy/bases/decretos/414-2009; and Reglamentacion de los arts. 37 a 40 de la ley 19.670 y art. 12 de la ley 18.331, referente a proteccion de datos personales (Decree 64/2020) [in Spanish]. Available at: https://www.impo.com.uy/bases/decretos/64-2020.
[cxv] Lucas, S. (2022) From data revolutionary to data governance advocate and back again: three lessons from the journey, William and Flora Hewlett Foundation, 21 January. Available at: https://hewlett.org/from-data-revolutionary-to-data-governance-advocate-and-back-again-three-lessons-from-the-journey/
[cxvi] Gathu, I. (2022) The #RestoreDataRights movement – a year into the new normal, Restore Data Rights, 19 January. Available at: https://restoredatarights.africa/a-year-into-the-new-normal/
[cxvii] Gathu, RestoreDataRights.
[cxviii] Yanez, L. and Letouzé, E. (2021) The CODE for building participatory and ethical data projects, Data Values Project, 3 August. Available at: https://www.data4sdgs.org/news/code-building-participatory-and-ethical-data-projects
[cxix]Yanez and Letouzé, Building participatory and ethical data.
[cxx]The First Nations Information Governance Centre (FNIGC) (2021?) The first nations principles of OCAP. Available at: https://fnigc.ca/ocap-training/
[cxxi] First Nations Information Governance Center (FNIGC) (2020?) Putting data to work: how quality information can (and is) changing First Nations communities, First Nations Information Governance Centre. Available at: https://fnigc.ca/wp-content/uploads/2020/09/75c69605182d6f914b5740446bb77e6c_fnigc_power_of_data_series_ottawa_0.pdf
[cxxii] See, for instance, the “Dignity Project” (https://dignityproject.net/our-research/), the “Connected by Data” initiative (https://connectedbydata.org/), and “The Eleanor Genome Protocol”, available at: Rathjen, Alice. (2022) “The Eleanor Genome Protocol.” Linkedin.com. https://www.linkedin.com/pulse/eleanor-genome-protocol-consent-alice-rathjen/
[cxxiii] Barzelay, A., Veerappan, M., and Lucey, M. (2021) Promoting trust in data through multistakeholder data governance, World Bank Blogs, 13 December. Available at: https://blogs.worldbank.org/opendata/promoting-trust-data-through-multistakeholder-data-governance
[cxxiv] Hardinges, J. and Keller, J.D. (2021) What are data institutions and why are they important?, The Open Data Institute, 29 January. Available at: https://theodi.org/article/what-are-data-institutions-and-why-are-they-important/
[cxxv] Data Trusts can be defined as “legal structure[s] that provides independent stewardship of data.” Definition taken from Hardinges, J. (2018) What is a data trust, The Open Data Institute, 10 July. Available at: https://theodi.org/article/what-is-a-data-trust/
[cxxvi] Data Cooperatives can be defined as “voluntary collaborative pooling by individuals of their personal data for the benefit of the membership of the group or community”. Definition taken from Pentland, A. and Hardjono, T. (2021) Data cooperatives in Building the new economy. Works in Progress [online]. Available at: https://wip.mitpress.mit.edu/pub/pnxgvubq/release/2
[cxxvii] World Economic Forum (2022) Advancing digital agency: the power of data intermediaries. World Economic Forum [online]. Available at: https://www3.weforum.org/docs/WEF_Advancing_towards_Digital_Agency_2022.pdf
[cxxviii] Young, A., Verhulst, S., Safonova, N., and Zahuranec, A. (2020) The data assembly - responsible data re-use framework. The Gov Lab and Henry Luce Foundation [online]. Available at: https://thedataassembly.org/files/nyc-data-assembly-report.pdf
[cxxix] Data Collaboratives can be defined as “new form[s] of collaboration, beyond the public-private partnership model, in which participants from different sectors — including private companies, research institutions, and government agencies — can exchange data to help solve public problems.” Definition taken from Verhulst, S. and Sangokoya, D. (2015) Data collaboratives: exchanging data to improve people’s lives’, Medium, 22 April. Available at: https://sverhulst.medium.com/data-collaboratives-exchanging-data-to-improve-people-s-lives-d0fcfc1bdd9a#:~:text=The%20term%20data%20collaborative%20refers,to%20help%20solve%20public%20problems.
[cxxx] The Global Partnership for Sustainable Development Data, We are here! Fireside chat; United Nations World Data Forum (2021) The Data Values Project - redefining what it means to live in a digital society programme, 3 October – 6 October. Available at: https://unstats.un.org/unsd/undataforum/bern-2021/programme/
[cxxxi] The Global Partnership, We are here! Fireside chat.
[cxxxii] International Work Group for Indigenous Affairs (IWGIA) (2021) The Indigenous world 2021: Indigenous data sovereignty, 18 March. Available at: https://www.iwgia.org/en/ip-i-iw/4268-iw-2021-indigenous-data-sovereignty.html
[cxxxiii] Amnesty International (2021) ‘Kenyans still unaware of data protection and right to privacy,’ Amnesty International [online]. https://www.amnestykenya.org/kenyans-still-unaware-of-data-protection-and-right-to-privacy/
[cxxxiv] Individuals’ interest in governing their data is evidenced by the rapid spur of individual data governance apps such as Rita Personal Data, Mine, OwnYourData, and others. Such apps allow individuals to collect, view, and control the personal information they share online.
[cxxxv] Global Partnership for Sustainable Development Data (GPSDD) (2020) Unlocking privately-held data for public good. Available at: https://www.data4sdgs.org/index.php/initiatives/unlocking-privately-held-data-public-good
[cxxxvi] Omino, M. and Rutenberg, I. (2021) Why the US-Kenya free trade agreement negotiations set a bad precedent for data policy, Center for Global Development, 1 June. Available at: https://www.cgdev.org/blog/why-us-kenya-free-trade-agreement-negotiations-set-bad-precedent-data-policy
[cxxxvii]Richards, K. (2022) The practical and ethical implications of inclusive data, Data Values Digest, 17 January. Available at: https://datavaluesdigest.substack.com/p/the-practical-and-ethical-implications?s=r
[cxxxviii] IEAG, A world that counts.
[cxxxix] Barbero, M. (2022) Embedding data use in development practices, Global Partnership for Sustainable Development Data, 26 January. Available at: https://www.data4sdgs.org/resources/embedding-data-use-development-practices
[cxl] Orrell, T. (2021) Towards a framework for governing data innovation: fostering trust in the use of non-traditional data sources in statistical production. Data Ready, Thematic Research Network on Data and Statistics, and Open Data [online]. Available at: https://static1.squarespace.com/static/5b4f63e14eddec374f416232/t/6061c9994f9237430a22291d/1617021339239/Trust+in+Statistics-L3.pdf
[cxli] Mayer-Schönberger, V., and Ramge, T. (2022) The data boom is here-it's just not evenly distributed, MIT Sloan Management Review, 63(3), pp. 7-9. Available at: https://sloanreview.mit.edu/article/the-data-boom-is-here-its-just-not-evenly-distributed/
[cxlii] Merino Márquez, A., (2022) Covid-19 contact tracing apps: a €100m failure, VoxEurope English, 19 January. Available at:https://voxeurop.eu/en/covid-19-track-trace-apps-a-100m-failure/
[cxliii] Poynter (202-) Fighting the infodemic: the #CoronaVirusFacts alliance. Available at: https://www.poynter.org/coronavirusfactsalliance/
[cxliv] Estrin, D. (2021) What to know about the spying scandal linked to Israeli tech firm NSO, NPR, 25 August. Available at: https://www.npr.org/2021/08/25/1027397544/nso-group-pegasus-spyware-mobile-israel
[cxlv] de Alarcon, P., Salevsky, A., Gheti-Kao, D., Rosalen, W., Duarte, M., Cuervo, C., Muñoz, J., Pascual, J., Schurig, M., Treß, T., Diaz, E., Cuesta, C., and Frias-Martinez, E. (2021) The contribution of telco data to fight the COVID-19 pandemic: experience of telefonica throughout its footprint, Data & Policy, 3(7), pp. 1-18. Available at: doi:10.1017/dap.2021.6.
[cxlvi] de Alrcon, et al., The contribution of telco data.
[cxlvii] Barbero, M. (2021) How can governments gain access to data from phone companies? A look into the future of public-private data sharing, Global Partnership for Sustainable Development Data, 11 October. Available at: https://www.data4sdgs.org/index.php/news/how-can-governments-gain-access-data-phone-companies-look-future-public-private-data-sharing
[cxlviii] Barbero, M. (2022) Key lessons from the EU Data Act proposal, Global Partnership for Sustainable Development Data, 15 March. Available at: https://www.data4sdgs.org/news/key-lessons-eu-data-act-proposal
[cxlix] Ramage, S. and Slotin, J. (2021) Why people are essential in data interoperability, Global Partnership for Sustainable Development Data, 25 August. Available at: https://www.data4sdgs.org/news/why-people-are-essential-data-interoperability
[cl] The Global Partnership for Sustainable Development Data, ASDSP, NIRAS, ESRI, Thunderbird School of Global Management, Sustainet Group, and the Ministry of Agriculture, Livestock, Fisheries and Cooperatives (2018) Real-time agriculture data for COVID-19 response in Kenya, The Global Partnership for Sustainable Development Data [online]. Available at: https://www.data4sdgs.org/sites/default/files/file_uploads/Real-time%20Ag%20Kenya%20COVID-19_0.pdf
[cli] The Global Partnership for Sustainable Development Data (GPSDD) (2021) From local needs to local knowledge: better data to end hunger, GPSDD [online]. Available at: https://www.data4sdgs.org/sites/default/files/2021-07/From%20Local%20Needs%20to%20Local%20Knowledge-%20Better%20data%20to%20End%20Hunger_July%202021.pdf
[clii]Open Data Institute (2021) Our theory of change. Available at: https://theodi.org/about-the-odi/our-vision-and-manifesto/our-theory-of-change/#1531394343060-45b9d19a-7776
[cliii] Data Values Project Focus Group Discussions with multilateral organizations, civil society organizations and donors (2021) Barriers and challenges for the use of data at the local level, 21 July, 22 September, and 29 September.
[cliv] Pybus, J., Coté, M., and Blanke, T. (2015) Hacking the social life of big data, Big Data & Society, 2(2), pp. 1-10. Available at: https://doi.org/10.1177/2053951715616649
[clv] Bhargava, R., Deahl, E., Letouzé, E., Noonan, A., Sangokoya, D., Shoup, N., Internews Center for Innovation and Learning, and the MIT Media Lab Center for Civic Media (2015) Beyond data literacy: reinventing community engagement and empowerment in the age of data. Data Pop Alliance [online]. Available at: https://datapopalliance.org/item/beyond-data-literacy-reinventing-community-engagement-and-empowerment-in-the-age-of-data/
[clvi] Paris 21 (2021) ‘Advancing data literacy in the post-pandemic world,’ Paris 21 [online]. https://paris21.org/sites/default/files/inline-files/DataLiteracy_Primer_0.pdf
[clvii] Global Partnership for Sustainable Data and Thematic Research Network on Data and Statistics (SDSN TReNDS) (2018) BudgIT empowers Nigerian citizens through open data. Global Partnership for Sustainable Data and SDSN TReNDS [online]. Available at: https://www.data4sdgs.org/sites/default/files/2018-09/BudgIT%20Case%20Study_Final.pdf
[clviii]Afadzinu, N. (2020) Going beyond Western models of value to shift the power, Bond, 16 January. Available at: https://www.bond.org.uk/news/2020/01/going-beyond-western-models-of-value-to-shift-the-power
[clix]Richards, K. (2022) The practical and ethical implications of inclusive data, Data Values Digest, 17 January. Available at:https://datavaluesdigest.substack.com/p/the-practical-and-ethical-implications?s=r
[clx] GPSDD, Why we should all be activists.
[clxi] Schweinfest, S., and Jansen, R. (2021) Data science and official statistics: toward a new data culture, Harvard Data Science Review, 3(4). Available at: https://doi.org/10.1162/99608f92.c1237762
[clxii] Govlab, Roles and responsibilities of data stewards.