
This piece was originally published on Azavea's website.
Africa, like most of the developing world, has a data problem. A shortage of available data ties the hands of researchers looking to perform the kind of high-quality studies that are needed to help devise useful policy. Remote sensing should provide a means to equalize some of the data disparity between the global North and South (after all, satellite trajectories do not discriminate), but it takes more than a cache of imagery to fix the problem. These data require some fairly intense processing to become usable information, and that processing often does not come cheap. This can be a problem for groups working in cash-strapped Africa.
Azavea believes that there is an opportunity for open source tools to make a difference in supporting this type of work. We were given a chance to test this idea when our VP of Research, Rob Emanuele, made the acquaintance of the principal investigator with the Agricultural Impacts Research Group at Clark University, Lyndon Estes. Lyndon was looking to expand upon a proof-of-concept project to detect smallholder agricultural fields (small farms usually supporting a single family) from WorldView-2 imagery.
Despite the promising early results of this research, scaling up to much larger inputs revealed the seams in their codebase. This is where Azavea comes in. With a generous grant from the Omidyar Network, Lyndon and his team were able to harness Azavea’s experience with big data raster processing and its open source tools like GeoTrellis to substantially clean up their prototype and get it ready for production.
The active learning mapping application
The other central methodological approach was to use an “active learning” process to refine the training set. Human mappers received unmapped areas that the machine learning model was the least certain about. These areas were then labeled and added to the training set.
Azavea was able to help the efforts on the mapping application by both creating a cloud free mosaic of Planet Labs’ PlanetScope data, and by using Raster Foundry to catalogue and serve out the images in true color and false color NDVI to the mapping application.
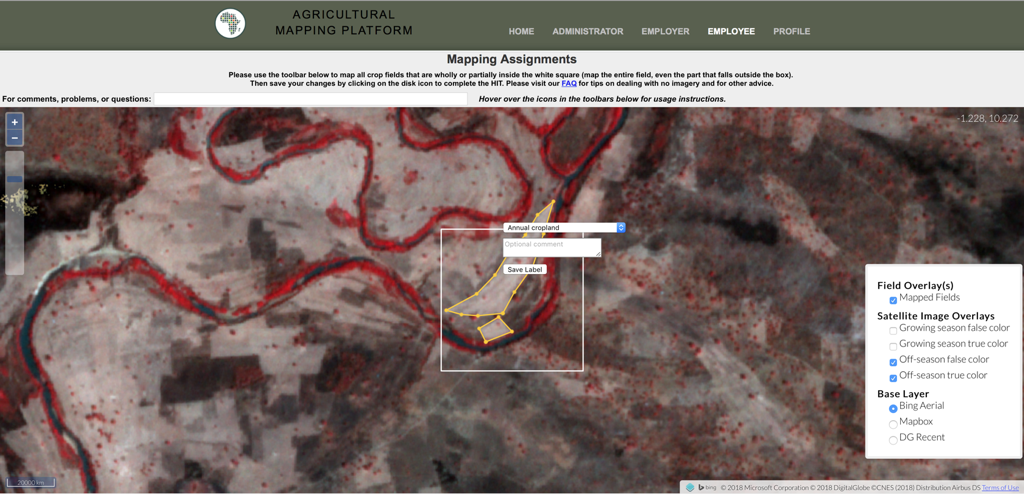
Credit: Azavea
A workflow based on Cloud Optimized GeoTIFFs
For us, the task list was simple:
- Create a cloud-free feature source from the PlanetScope imagery
- Train and apply a machine learning model
- Deliver the final classifications as imagery suitable for visualization
But this project ended up requiring us to reevaluate some of our core tools and establish a new approach to analysis. As the entire GIS community becomes more focused on applications that rely on cloud-native geospatial, there has been a push to adopt Cloud-Optimized GeoTIFFs, or COGs, as an imagery source. Rather than building specialized catalogs of image tiles—requiring an ETL process and, sometimes, custom file formats—we want to point to a COG (or a collection of COGs) and be able to query those files directly with minimal fuss. This improves portability and ease of use, without substantially affecting performance.
Azavea has been part of the push towards cloud-native geospatial and COG-oriented workflows. But it was only with the release of GeoTrellis 2.0 in August 2018 that COG become a core building block of the library. This project provided a helpful challenge to help shape and test the requisite tooling.
A cloud-free mosaic
The classification algorithm had simple demands: two base maps of satellite imagery with one covering the growing season (December–April) and one covering the off season (July–November). The master grid—specifying the size, extent, and resolution of the tiles—was defined, and each cell would need to have associated with it a pair of PlanetScope images, one for each season, but these data were still safely stowed on Planet’s servers. We wrote an application to mine Planet’s catalog for imagery that intersected an area of interest and associated with each tile the newest image for each season that covered the tile and passed a cloud-free test furnished by our friends at Clark. The result was a minimal catalog of COGs that we could use as input to the classifier.
Finding fields with random forests
The consumer for this imagery is a random forest classifier following the prototype provided by our collaborators. But in order to build a system that scaled well and was easy to maintain, we wanted to shift over to a system that naturally bridged between the machine learning apparatus provided by SparkML and the raster-processing infrastructure of Geotrellis. Our comrades-in-arms at Astraea, fortunately, have this handled. We used their RasterFrames project to give us native access to Geotrellis tiles in a Spark DataFrame and also to help convert the pixel data into a form usable by SparkML. This would end up being less straightforward than it sounds, due to the COG-based catalog.
We settled on using rasterio to perform a resampling windowed read of the COGs and GeoPySpark to manage the conversion to a RasterFrame and from a RasterFrame to a COG catalog on the output side. The model required us to extend RasterFrames as well, incorporating a prototype implementation of focal operations into the library—an implementation that we’ll be working to move into the upstream version over the coming year. The bulk of the application itself was straightforward to write, and performed as expected, despite the number of custom solutions needed to work around the technical requirements for the project. This will serve as a solid foundation for the project that can grow and improve as Lyndon and his team push the work forward. (It also provides a template for improvements to Geotrellis and RasterFrames to make this kind of workflow more natural. Stay tuned!)
Results
We concluded our part of this project in the fall of 2018, and the Clark crew have been at work with their team of mappers in Africa supplying training data and refining their model. The results are coming in, and it seems promising, as can be seen by the images below.
In the future, the source for much of this work will be released to the public under the agroimpacts GH repo. Naturally, there are still problems to solve, but the project is now on a solid footing to start contributing real data to the study of agriculture in Africa.

(Identifying fields in Northern Ghana [Growing season, off growing season, pixel-based predictions.]) Credit: Azavea

(Identifying fields in Southern Ghana [Growing season, off growing season, pixel-based predictions.]) Credit: Azavea
Special thanks
This was a great opportunity to work with a talented team of researchers. We are glad the relationship was mutually beneficial. Says, Lyndon; “We are very excited to continue refining and applying our platform, which we intend to use to produce high accuracy, high resolution cropland maps for all of Ghana by the end of this year. We feel confident that we can achieve this goal, now that we have the highly scalable and robust machine learning pipeline developed by Azavea. Their effort in developing this went far above and beyond what we all initially imagined would be the scope of effort, and is thus a really critical contribution to our project’s success.”